OLMo 2 1124 7B Preference Mixture
OLMo 2 1124 7B Preference Mixture官网入口
OLMo 2 1124 7B Preference Mixture登录网址
自然语言处理
文本数据集
偏好学习
用户意图理解
机器学习
AI办公应用
AI数据分析
OLMo 2 1124 7B Preference Mixture是什么,是做什么的AI工具软件?
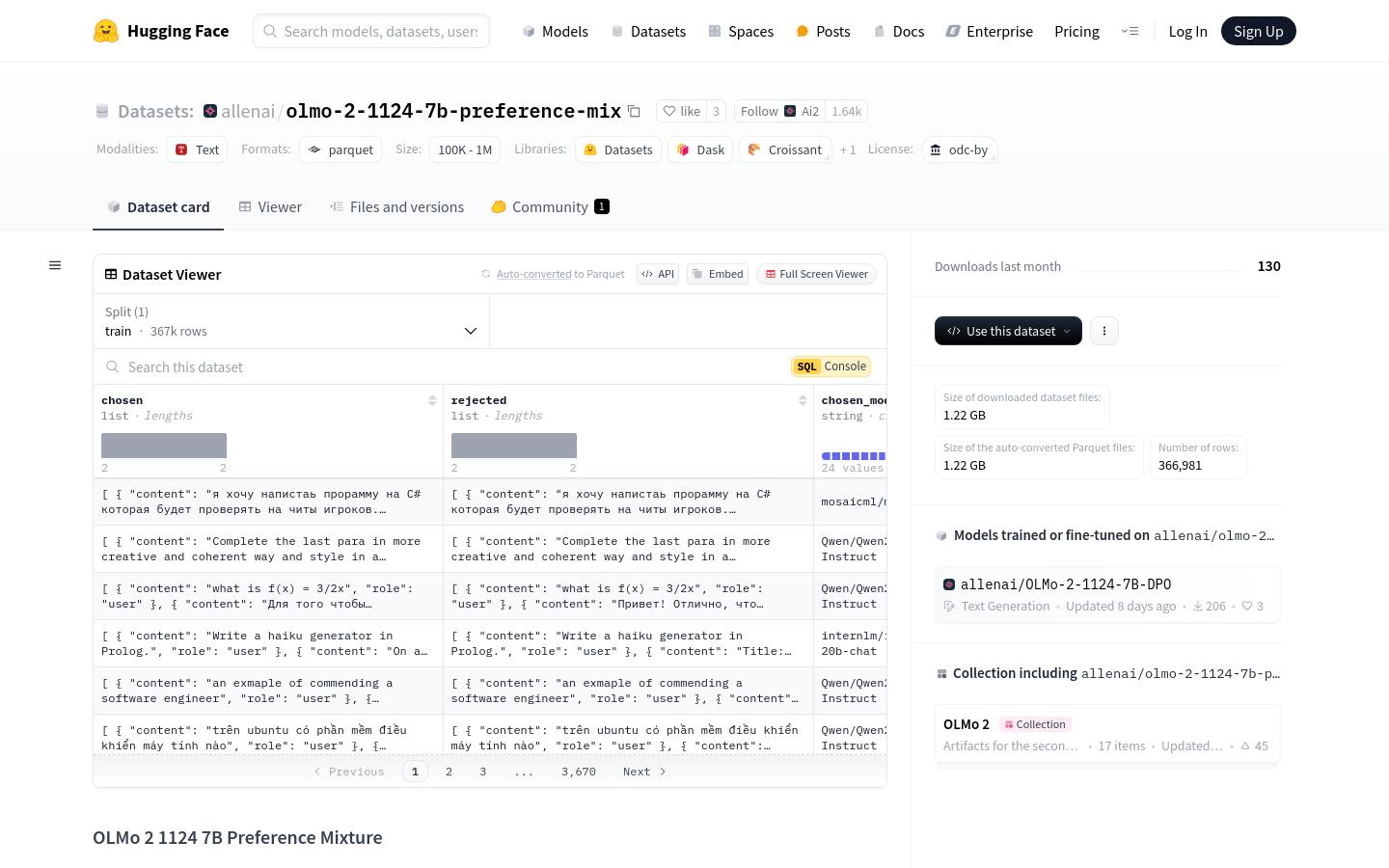
OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。
需求人群:
"目标受众为自然语言处理领域的研究人员、开发者和教育工作者。这个数据集适合他们,因为它提供了大量的文本数据,可以用来训练和测试语言模型,特别是在理解和预测用户偏好方面。此外,数据集的多样性也使其成为研究不同语言使用场景的理想选择。"
使用场景示例:
研究人员使用该数据集来训练聊天机器人,以更好地理解用户的查询意图。
开发者利用数据集中的对话数据来优化语音助手的响应准确性。
教育工作者使用该数据集来教授学生如何构建和评估自然语言处理模型。
产品特色:
包含多个来源的数据,用于构建全面的偏好学习模型
支持自然语言处理模型的训练和微调
适用于研究用户意图和偏好的混合
数据集包含366.7k个生成对,覆盖广泛的语言使用场景
适用于教育和研究领域,帮助理解语言模型的行为
数据集可用于开发聊天机器人和其他交互式应用
支持多种自然语言处理任务,如文本分类、情感分析等
数据集遵循ODC-BY许可,适用于研究和教育用途
使用教程:
1. 访问 Hugging Face 数据集页面并下载所需的数据集文件。
2. 根据项目需求,选择合适的模型和工具来处理数据集。
3. 使用数据集训练或微调自然语言处理模型。
4. 分析模型输出,调整参数以优化性能。
5. 将训练好的模型应用于实际问题,如聊天机器人开发或文本分析。
6. 根据需要,对数据集进行进一步的清洗和预处理。
7. 记录实验结果,并根据反馈迭代改进模型。
-
 PK
PK OLMo 2 1124 7B Preference Mixture VS Capacities
OLMo 2 1124 7B Preference Mixture VS CapacitiesOLMo 2 1124 7B Preference Mixture:OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。 ...
Capacities:Capacities是一个旨在改善人们思考方式和工作流程的应用程序。它通过使用对象而非传统文件和文件夹来组织信息,帮助用户更直观地理解和连接复杂的信息结构。该应用支持网络化笔记,使用户能够自然地构建信息网络,激发新的创意。Capacities还提供AI助手,帮助用户与笔记中的对象动态互动,并提高写作质量。此外,该应用注重数据安全和隐私保护,符合GDPR标准,数据存储在欧盟的加密服务器上。 ...
-
PK
 OLMo 2 1124 7B Preference Mixture VS AI Generated Diagram
OLMo 2 1124 7B Preference Mixture VS AI Generated DiagramOLMo 2 1124 7B Preference Mixture:OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。 ...
AI Generated Diagram:AI Generated Diagram 是一款利用人工智能技术生成图表的工具。它通过用户输入的提示(prompts)来创建图表,支持多种布局类型,如水平布局(Horizontal)。用户可以通过编辑、配置等操作来调整图表的细节,并支持导出为SVG格式或导出数据。该工具不仅提高了设计图表的效率,还通过AI技术提升了图表的美观度和准确性。 ...
-
PK
 OLMo 2 1124 7B Preference Mixture VS Airtable Cobuilder
OLMo 2 1124 7B Preference Mixture VS Airtable CobuilderOLMo 2 1124 7B Preference Mixture:OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。 ...
Airtable Cobuilder:Airtable Cobuilder 是一款强大的应用程序构建工具,旨在通过简单的拖放界面和AI辅助功能,帮助用户快速创建和管理数据。它允许用户连接和简化他们最关键的数据,通过可视化数据、自定义视图和集成其他业务工具,提高团队协作和数据管理的效率。该工具特别适合需要高度定制化和灵活性的业务应用场景。 ...
-
PK
 OLMo 2 1124 7B Preference Mixture VS ReviewHawk
OLMo 2 1124 7B Preference Mixture VS ReviewHawkOLMo 2 1124 7B Preference Mixture:OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。 ...
ReviewHawk:ReviewHawk是一个专注于分析应用商店评论的工具,旨在帮助企业降低用户流失率,获取用户反馈,从而改善产品。它通过数据驱动的决策和用户满意度分析,帮助企业了解用户真正想要的功能,从而提升用户留存率和产品满意度。 ...
-
PK
 OLMo 2 1124 7B Preference Mixture VS ZETIC.ai
OLMo 2 1124 7B Preference Mixture VS ZETIC.aiOLMo 2 1124 7B Preference Mixture:OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。 ...
ZETIC.ai:ZETIC.ai提供了一种革命性的设备端AI解决方案,使用NPU技术帮助企业减少对GPU服务器和AI云服务的依赖,从而显著降低成本。它支持任何操作系统、任何处理器和任何目标设备,确保AI模型在转换过程中不损失任何核心功能,同时实现最优性能和最大能效。此外,它还增强了数据安全性,因为数据在设备内部处理,避免了外部泄露的风险。 ...
-
PK
 OLMo 2 1124 7B Preference Mixture VS Kipps.AI
OLMo 2 1124 7B Preference Mixture VS Kipps.AIOLMo 2 1124 7B Preference Mixture:OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。 ...
Kipps.AI:Kipps.AI 是一个在线平台,允许用户在短短两分钟内构建自己的AI助手,并将其集成到业务中。该平台支持多种数据源,如PDF、Notion、网站链接和文本,用户只需提供这些数据,Kipps.AI 会处理其余部分。它还与常用的工具如GoDaddy、Wordpress、Drupal、Squarespace、Magento和Wix等进行集成,使得用户可以轻松地将AI助手集成到现有的业务流程中。 ...
-
PK
 OLMo 2 1124 7B Preference Mixture VS Klee
OLMo 2 1124 7B Preference Mixture VS KleeOLMo 2 1124 7B Preference Mixture:OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。 ...
Klee:Klee是一款macOS原生的AI助手应用程序,专注于本地处理数据,确保数据安全和隐私。它使用先进的AI技术,如RAG(检索增强生成)和开源大型语言模型,如Llama 3和Mistral,为用户提供高效、智能的笔记、搜索和知识管理功能。Klee的主要优点包括本地运行以保护隐私、支持团队协作、免费使用以及优化的macOS体验。 ...
-
PK
 OLMo 2 1124 7B Preference Mixture VS Husky-v1
OLMo 2 1124 7B Preference Mixture VS Husky-v1OLMo 2 1124 7B Preference Mixture:OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。 ...
Husky-v1:Husky-v1是一个开源的语言代理模型,专注于解决包含数值、表格和基于知识的复杂多步推理任务。它使用工具使用、代码生成器、查询生成器和数学推理器等专家模型来执行推理。此模型支持CUDA 11.8,需要下载相应的模型文件,并可以通过优化的推理过程并行运行所有专家模型。 ...
-
PK
 OLMo 2 1124 7B Preference Mixture VS Smart AI Survey
OLMo 2 1124 7B Preference Mixture VS Smart AI SurveyOLMo 2 1124 7B Preference Mixture:OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。 ...
Smart AI Survey:Smart AI Survey是一款结合AI驱动的问卷调查和数据分析的工具,能够从开放式问题和答案中快速生成洞见。它提供实时答案验证和深入访谈,确保高质量响应。AI数据分析能够识别主题和洞见,提供对数据的更深层次理解。该工具覆盖从收集商店体验的事实到衡量青少年护肤意见的使用案例,能够即时链接定量和定性数据。此外,洞见可以实时与受访者和用户共享。 ...
-
PK
 OLMo 2 1124 7B Preference Mixture VS Exifaa
OLMo 2 1124 7B Preference Mixture VS ExifaaOLMo 2 1124 7B Preference Mixture:OLMo 2 1124 7B Preference Mixture 是一个大规模的文本数据集,由 Hugging Face 提供,包含366.7k个生成对。该数据集用于训练和微调自然语言处理模型,特别是在偏好学习和用户意图理解方面。它结合了多个来源的数据,包括SFT混合数据、WildChat数据以及DaringAnteater数据,覆盖了广泛的语言使用场景和用户交互模式。 ...
Exifaa:Exifaa是一个在线的图片元数据编辑器,它允许用户轻松地查看、编辑和删除图片的EXIF信息。EXIF信息包括相机型号、拍摄时间、GPS位置等,对于摄影爱好者和专业摄影师来说,管理这些信息至关重要。Exifaa以其简洁的界面和强大的功能,为用户提供了一个方便快捷的解决方案。 ...
卓商AI整理了一些与 OLMo 2 1124 7B Preference Mixture 功能相似或可平替的站点应用,您可点击列表中的标题即可对比查看详细介绍。
相关AI工具集
-
CapacitiesCapacities是一个旨在改善人们思考方式和工作流程的应用程序。它通过使用对象而非传统文件和文件夹来组织信息,帮助用户更直观地理解和连接复杂的信息...
-
AI Generated DiagramAI Generated Diagram 是一款利用人工智能技术生成图表的工具。它通过用户输入的提示(prompts)来创建图表,支持多种布局类型,如...
-
Airtable CobuilderAirtable Cobuilder 是一款强大的应用程序构建工具,旨在通过简单的拖放界面和AI辅助功能,帮助用户快速创建和管理数据。它允许用户连接和...
-
ReviewHawkReviewHawk是一个专注于分析应用商店评论的工具,旨在帮助企业降低用户流失率,获取用户反馈,从而改善产品。它通过数据驱动的决策和用户满意度分析,...
-
ZETIC.aiZETIC.ai提供了一种革命性的设备端AI解决方案,使用NPU技术帮助企业减少对GPU服务器和AI云服务的依赖,从而显著降低成本。它支持任何操作系统...
-
Kipps.AIKipps.AI 是一个在线平台,允许用户在短短两分钟内构建自己的AI助手,并将其集成到业务中。该平台支持多种数据源,如PDF、Notion、网站链接...
-
KleeKlee是一款macOS原生的AI助手应用程序,专注于本地处理数据,确保数据安全和隐私。它使用先进的AI技术,如RAG(检索增强生成)和开源大型语言模...
-
Husky-v1Husky-v1是一个开源的语言代理模型,专注于解决包含数值、表格和基于知识的复杂多步推理任务。它使用工具使用、代码生成器、查询生成器和数学推理器等专...
-
Smart AI SurveySmart AI Survey是一款结合AI驱动的问卷调查和数据分析的工具,能够从开放式问题和答案中快速生成洞见。它提供实时答案验证和深入访谈,确保高...
-
ExifaaExifaa是一个在线的图片元数据编辑器,它允许用户轻松地查看、编辑和删除图片的EXIF信息。EXIF信息包括相机型号、拍摄时间、GPS位置等,对于摄...
-
 Segment Anything Model 2Segment Anything Model 2 (SAM 2)是Meta公司AI研究部门FAIR推出的一个视觉分割模型,它通过简单的变换器架构和流式...
Segment Anything Model 2Segment Anything Model 2 (SAM 2)是Meta公司AI研究部门FAIR推出的一个视觉分割模型,它通过简单的变换器架构和流式... -
 SA-V DatasetSA-V Dataset是一个专为训练通用目标分割模型设计的开放世界视频数据集,包含51K个多样化视频和643K个时空分割掩模(masklets)。该...
SA-V DatasetSA-V Dataset是一个专为训练通用目标分割模型设计的开放世界视频数据集,包含51K个多样化视频和643K个时空分割掩模(masklets)。该...

卓商AI
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
最新收录
Spoke
Spoke是一款AI插件,为产品经理提供强大的、注重隐私的AI功能,能够在几秒钟内为用户提供上下文信息。它可以帮助全球快速增长的团队节省时间,创造上下...
LastMile AI
LastMile AI是一个AI开发平台,专为工程师而设计,可以用于原型开发和生成式AI应用的生产。它提供了一站式的多模态AI模型访问,包括语言模型(...
Dokkio
Dokkio是一款利用人工智能技术提供云文件协作的工具。它能帮助用户管理多个活动、搜索文档和文件、整理研究材料、组织内容库,并将所有文件和内容集中在一...

Engage Sphere AI
Engage Sphere是一个基于AI的员工参与度分析平台。它可以深入分析公司各个部门、团队和岗位的参与度,帮助管理者明确团队互动症结所在,并采取行...
Pikzels
Pikzels连接顶级人才和有远见的客户。我们促进协作,释放创意卓越。加入我们,获取来自各个领域的优秀专业人才。体验协作的力量,释放你的创意潜能。Pi...
Zoho Cliq
Zoho Cliq是一款专为提高企业工作效率而设计的在线即时通讯和协作平台。它将团队成员、对话和工作流集中在一个地方,实现无缝连接。主要功能包括:组织...
猜你喜欢
Spoke
Spoke是一款AI插件,为产品经理提供强大的、注重隐私的AI功能,能够在几秒钟内为用户提供上下文信息。它可以帮助全球快速增长的团队节省时间,创造上下...
LastMile AI
LastMile AI是一个AI开发平台,专为工程师而设计,可以用于原型开发和生成式AI应用的生产。它提供了一站式的多模态AI模型访问,包括语言模型(...
Dokkio
Dokkio是一款利用人工智能技术提供云文件协作的工具。它能帮助用户管理多个活动、搜索文档和文件、整理研究材料、组织内容库,并将所有文件和内容集中在一...
Engage Sphere AI
Engage Sphere是一个基于AI的员工参与度分析平台。它可以深入分析公司各个部门、团队和岗位的参与度,帮助管理者明确团队互动症结所在,并采取行...
Pikzels
Pikzels连接顶级人才和有远见的客户。我们促进协作,释放创意卓越。加入我们,获取来自各个领域的优秀专业人才。体验协作的力量,释放你的创意潜能。Pi...
Zoho Cliq
Zoho Cliq是一款专为提高企业工作效率而设计的在线即时通讯和协作平台。它将团队成员、对话和工作流集中在一个地方,实现无缝连接。主要功能包括:组织...
最新文章
1
2
3
4
5
6
7
8
9
10
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
