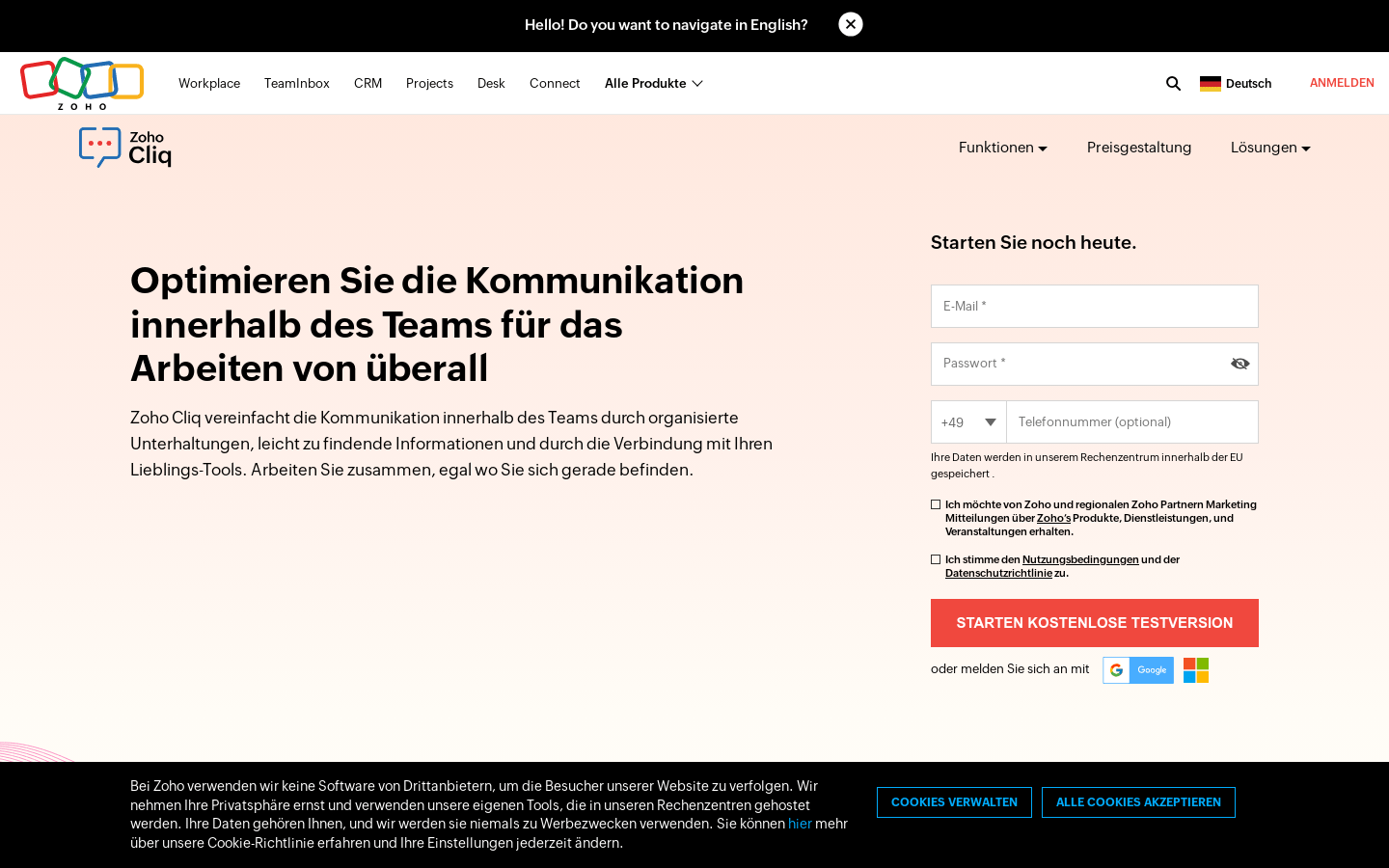
UniMuMo简介概述
UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。
需求人群:
"目标受众包括音乐制作人、舞蹈编导、视频游戏开发者、虚拟现实内容创作者和任何需要生成或同步音乐、文本和动作数据的专业人士。UniMuMo能够提供跨模态的创作工具,帮助他们更高效地创作和实现创意。"
使用场景示例:
音乐制作人利用UniMuMo根据文本描述生成音乐和舞蹈动作。
视频游戏开发者使用UniMuMo为游戏中的NPC生成同步的音乐和动作。
虚拟现实内容创作者使用UniMuMo为虚拟角色生成自然的动作和音乐反应。
产品特色:
支持文本、音乐和动作数据的输入条件,生成跨模态的输出。
通过节奏模式对未配对的音乐和动作数据进行对齐,利用现有的大规模音乐和动作数据集。
采用统一的编码器-解码器转换器架构,将音乐、动作和文本桥接。
提出了音乐运动并行生成方案,将所有音乐和动作生成任务统一到单一的转换器解码器架构中。
通过微调现有的预训练单模态模型来设计模型,显著降低了计算需求。
在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。
使用教程:
访问UniMuMo的在线演示页面。
阅读页面上的介绍,了解模型的功能和背景。
根据需要选择输入模态,如文本、音乐或动作。
输入具体的文本描述、音乐片段或动作数据。
提交输入数据,等待模型生成跨模态的输出。
查看生成的结果,如音乐、动作或文本描述。
根据需要调整输入数据或参数,重复生成过程以获得更满意的结果。
-
 PK
PK UniMuMo VS Revocalize AI
UniMuMo VS Revocalize AIUniMuMo:UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。 ...
Revocalize AI:Revocalize AI 是一款音乐制作与处理工具,能够作为声音美化器、合成器、和均衡器,为声音带来全新的革命性体验。它就像是 Photoshop 一样,但专注于声音。\n\nRevocalize AI 可以训练自定义的 AI 声音模型,也可以使用其他模型来生成逼真而美妙的声音轨。用户可以通过这款工具在声音处理领域迈向未来。\n\n 主要功能:\n- 声音合成,不受限制 \n- 无尽的声音可能性 \n- 终极的情感表达 \n- 语言多样性 \n- 实时自动调音 \n- 自动生成声音变化 \n- 专业声音调制 \n\nRevocalize AI 已被 10,000 多名艺术家、品牌和开发者所信任,共同构建未来的声音世界。 ...
-
PK
 UniMuMo VS SongR
UniMuMo VS SongRUniMuMo:UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。 ...
SongR:SongR 是一款全能的 AI 文本转歌曲软件,通过简单的几个关键词生成自定义歌词,并添加选定类型的人声和伴奏,为您创建独特的歌曲,可在社交媒体上分享。无需音乐经验,让每个人都能创作出独特的个性化歌曲。SongR 旨在为所有人民主化歌曲和音乐的创作。 ...
-
PK
 UniMuMo VS Voice-Swap
UniMuMo VS Voice-SwapUniMuMo:UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。 ...
Voice-Swap:Voice-Swap 是由 DJ Fresh 和 Nico Pellerin 设计的,旨在帮助那些不想在歌曲中使用自己声音的制作人、艺术家和作曲家,通过人工智能将他们的声音转化为像我们的特约艺术家之一的声音。你可以使用 Voice-Swap 制作演示音频,但不能公开分享或以任何方式进行商业化,除非购买许可证。我们的艺术家会在 48 小时内回复并接受请求,除非对歌词内容有道德或政治上的问题。你可以购买一次性许可证来购买歌手的所有权,以便你可以发布你的曲目。 ...
-
PK
 UniMuMo VS Pond5 Lullab.AI
UniMuMo VS Pond5 Lullab.AIUniMuMo:UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。 ...
Pond5 Lullab.AI:Pond5是全球最大的高清和4K库存视频库,同时还提供数百万音乐曲目、SFX、动态图形和图片。无论您是制作电影、广告、音乐视频还是其他创意项目,Pond5都可以满足您的需求。我们的库存视频涵盖了各种主题和风格,包括抽象、城市、自然、人物等。我们还提供专业品质的音乐曲目、音效和动态图形,帮助您为您的作品增添独特的音乐和视觉效果。Pond5的价格实惠,让您可以以合理的价格获取专业质量的媒体素材。无论您是专业制片人还是刚入门的创作者,Pond5都是您创作项目的完美伙伴。 ...
-
PK
 UniMuMo VS Musicfy
UniMuMo VS MusicfyUniMuMo:UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。 ...
Musicfy:Musicfy是一款AI音乐助手,可以用你的声音创作音乐。它提供AI音频转换功能,让你的歌曲听起来与众不同;可以上传你的声音创建自己的AI模型,让AI音乐听起来像你一样;还可以分离歌曲的不同音轨,提升音乐创作过程的效率。Musicfy节省宝贵的时间,促进协作,并确保艺术愿景的无缝对齐。加入我们,探索新的声音和创意! ...
-
PK
 UniMuMo VS Uberduck
UniMuMo VS UberduckUniMuMo:UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。 ...
Uberduck:Uberduck是一款AI声音合成工具,拥有5,000多个富有表达力的声音,可用于制作音乐和语音。它提供简单易用的API,可帮助开发者在几分钟内构建出色的音频应用程序。此外,Uberduck还支持定制声音克隆,用户可以合成出自己的声音。无论是制作音乐还是语音应用,Uberduck都能帮助用户实现个性化创作。 ...
-
PK
 UniMuMo VS Songtell
UniMuMo VS SongtellUniMuMo:UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。 ...
Songtell:Songtell是一款通过AI揭示你喜爱歌曲歌词背后真正含义的工具。它能帮助你深入了解喜欢的歌曲,揭示出其中引人入胜的故事和意义。你可以发现最新插入的歌曲意义,共有763,615条歌曲意义记录。Songtell让你更好地欣赏音乐。 ...
-
PK
 UniMuMo VS Lalal.ai
UniMuMo VS Lalal.aiUniMuMo:UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。 ...
Lalal.ai:LALAL.AI是一款下一代音乐分轨器和人声消除器,采用世界一流的AI技术,快速、简便、准确地分离音乐的不同部分。无损地去除人声、乐器、鼓、贝斯、钢琴、电吉他、原声吉他和合成器等轨道。 ...
-
PK
 UniMuMo VS Moises
UniMuMo VS MoisesUniMuMo:UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。 ...
Moises:Moises App是一款专为音乐家打造的应用程序,提供声音消除、乐器分离、音频处理等功能。使用AI技术,可以从任何歌曲中消除或分离人声和乐器,调整速度和音调,并提供节拍器功能。Moises App可以帮助音乐家在练习和创作中获得更好的体验。 ...
-
PK
 UniMuMo VS Soundraw
UniMuMo VS SoundrawUniMuMo:UniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示,通过统一的编码器-解码器转换器架构桥接这些模态。它通过微调现有的单模态预训练模型,显著降低了计算需求。UniMuMo在音乐、动作和文本模态的所有单向生成基准测试中都取得了有竞争力的结果。 ...
Soundraw:AI音乐生成器是您的个人AI音乐生成器,轻松创建音乐;提供视频授权、影视音乐、无版权音乐、视频订阅、视频音乐库、适用于YouTube视频的音乐等服务;提供个人计划和年度计划两种定价方案。 ...
卓商AI整理了一些与 UniMuMo 功能相似或可平替的站点应用,您可点击列表中的标题即可对比查看详细介绍。
-
Revocalize AIRevocalize AI 是一款音乐制作与处理工具,能够作为声音美化器、合成器、和均衡器,为声音带来全新的革命性体验。它就像是 Photoshop ...
-
SongRSongR 是一款全能的 AI 文本转歌曲软件,通过简单的几个关键词生成自定义歌词,并添加选定类型的人声和伴奏,为您创建独特的歌曲,可在社交媒体上分享...
-
Voice-SwapVoice-Swap 是由 DJ Fresh 和 Nico Pellerin 设计的,旨在帮助那些不想在歌曲中使用自己声音的制作人、艺术家和作曲家,通...
-
Pond5 Lullab.AIPond5是全球最大的高清和4K库存视频库,同时还提供数百万音乐曲目、SFX、动态图形和图片。无论您是制作电影、广告、音乐视频还是其他创意项目,Pon...
-
MusicfyMusicfy是一款AI音乐助手,可以用你的声音创作音乐。它提供AI音频转换功能,让你的歌曲听起来与众不同;可以上传你的声音创建自己的AI模型,让AI...
-
UberduckUberduck是一款AI声音合成工具,拥有5,000多个富有表达力的声音,可用于制作音乐和语音。它提供简单易用的API,可帮助开发者在几分钟内构建出...
-
SongtellSongtell是一款通过AI揭示你喜爱歌曲歌词背后真正含义的工具。它能帮助你深入了解喜欢的歌曲,揭示出其中引人入胜的故事和意义。你可以发现最新插入的...
-
Lalal.aiLALAL.AI是一款下一代音乐分轨器和人声消除器,采用世界一流的AI技术,快速、简便、准确地分离音乐的不同部分。无损地去除人声、乐器、鼓、贝斯、钢琴...
-
MoisesMoises App是一款专为音乐家打造的应用程序,提供声音消除、乐器分离、音频处理等功能。使用AI技术,可以从任何歌曲中消除或分离人声和乐器,调整速...
-
SoundrawAI音乐生成器是您的个人AI音乐生成器,轻松创建音乐;提供视频授权、影视音乐、无版权音乐、视频订阅、视频音乐库、适用于YouTube视频的音乐等服务;...
-
 Voicify.AIVoicify AI是一款AI音乐创作工具,能够使用AI翻唱创作高质量的AI翻唱歌曲。平台提供了上百个社区上传的AI声音模型供用户创作使用。Voici...
Voicify.AIVoicify AI是一款AI音乐创作工具,能够使用AI翻唱创作高质量的AI翻唱歌曲。平台提供了上百个社区上传的AI声音模型供用户创作使用。Voici... -
 LandrLANDR是为创作者提供的在线音乐软件,包括音乐母带处理、数字音乐分发、精选插件、免费采样包、合作工具、音乐推广等功能。价格合理,试用免费。...
LandrLANDR是为创作者提供的在线音乐软件,包括音乐母带处理、数字音乐分发、精选插件、免费采样包、合作工具、音乐推广等功能。价格合理,试用免费。...

AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。