收集全球10,000⁺个好用的AI软件
-
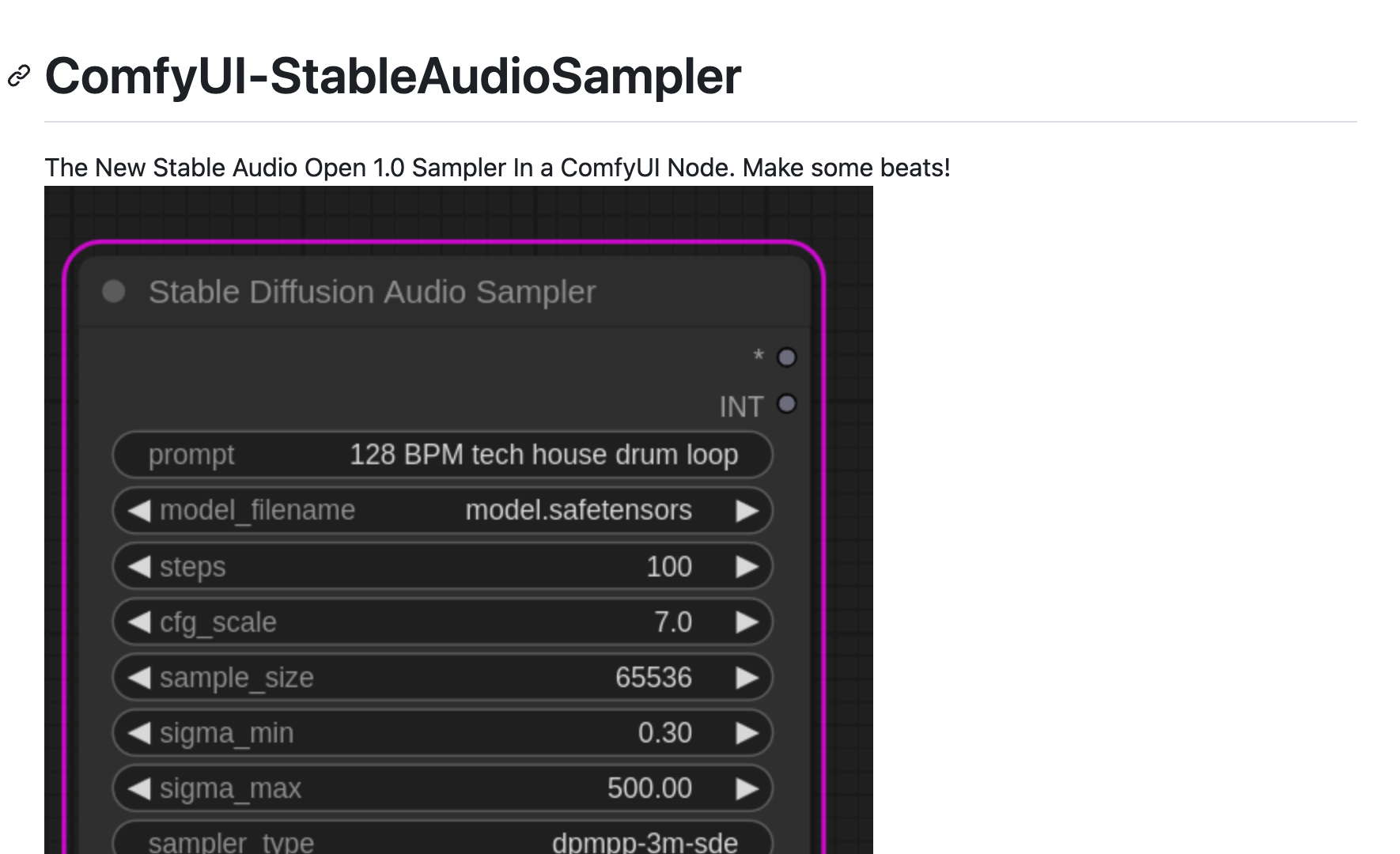 ComfyUI-StableAudioSamplerComfyUI-StableAudioSampler 是一款集成在 ComfyUI 节点中的音频采样器插件,它允许用户生成音频并输出原始字节和采样率,...
ComfyUI-StableAudioSamplerComfyUI-StableAudioSampler 是一款集成在 ComfyUI 节点中的音频采样器插件,它允许用户生成音频并输出原始字节和采样率,... -
 Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文...
Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文... -
 ElevenLabs Audio Isolation APIAudio Isolation 是 ElevenLabs 提供的一项在线音频处理服务,专注于从音频中分离出人声或背景音乐。这项技术在音乐制作、视频后期...
ElevenLabs Audio Isolation APIAudio Isolation 是 ElevenLabs 提供的一项在线音频处理服务,专注于从音频中分离出人声或背景音乐。这项技术在音乐制作、视频后期... -
 Qwen2-AudioQwen2-Audio是由阿里云提出的大型音频语言模型,能够接受各种音频信号输入,并根据语音指令进行音频分析或直接文本回复。该模型支持两种不同的音频交...
Qwen2-AudioQwen2-Audio是由阿里云提出的大型音频语言模型,能够接受各种音频信号输入,并根据语音指令进行音频分析或直接文本回复。该模型支持两种不同的音频交... -
 Audio ChatAudio Chat是一个专注于音频文件处理的网站,它允许用户上传讲座、会议或面试等音频文件,并进行对话分析。该产品通过先进的音频处理技术,帮助用户快...
Audio ChatAudio Chat是一个专注于音频文件处理的网站,它允许用户上传讲座、会议或面试等音频文件,并进行对话分析。该产品通过先进的音频处理技术,帮助用户快... -
 Easy Voice ToolkitEasy Voice Toolkit是一个基于开源语音项目的AI语音工具箱,提供包括语音模型训练在内的多种自动化音频工具。该工具箱能够无缝集成,形成完...
Easy Voice ToolkitEasy Voice Toolkit是一个基于开源语音项目的AI语音工具箱,提供包括语音模型训练在内的多种自动化音频工具。该工具箱能够无缝集成,形成完... -
 seed-vcseed-vc 是一个基于 SEED-TTS 架构的声音转换模型,能够实现零样本的声音转换,即无需特定人的声音样本即可转换声音。该技术在音频质量和音色...
seed-vcseed-vc 是一个基于 SEED-TTS 架构的声音转换模型,能够实现零样本的声音转换,即无需特定人的声音样本即可转换声音。该技术在音频质量和音色... -
 EzAudioEzAudio是一个先进的文本到音频(T2A)生成模型,它能够从文本提示中创建高质量的音频。它为开源T2A模型设定了新的标准,提供快速、高效和逼真的声...
EzAudioEzAudio是一个先进的文本到音频(T2A)生成模型,它能够从文本提示中创建高质量的音频。它为开源T2A模型设定了新的标准,提供快速、高效和逼真的声... -
 AILIBRIAILIBRI是一个汇集了超过2000个AI神经网络工具的目录网站,涵盖了文本、图像、视频、音频等多个领域的工具。它为用户寻找合适的AI工具提供了极大...
AILIBRIAILIBRI是一个汇集了超过2000个AI神经网络工具的目录网站,涵盖了文本、图像、视频、音频等多个领域的工具。它为用户寻找合适的AI工具提供了极大... -
 DiariZenDiariZen是一个基于AudioZen和Pyannote 3.1驱动的说话人分割工具包。说话人分割是音频处理中的一个关键步骤,它能够将一段音频中的...
DiariZenDiariZen是一个基于AudioZen和Pyannote 3.1驱动的说话人分割工具包。说话人分割是音频处理中的一个关键步骤,它能够将一段音频中的... -
 Universal-2Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复...
Universal-2Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复... -
 Browser AI KitBrowser AI Kit是一个集成了多种AI工具的平台,用户可以在浏览器中直接使用这些工具,无需安装或设置。它提供了音频转文本、去除背景、文本转语...
Browser AI KitBrowser AI Kit是一个集成了多种AI工具的平台,用户可以在浏览器中直接使用这些工具,无需安装或设置。它提供了音频转文本、去除背景、文本转语... -
 Fish Agent V0.1 3BFish Agent V0.1 3B是一个开创性的语音转语音模型,能够以前所未有的精确度捕捉和生成环境音频信息。该模型采用了无语义标记架构,消除了传统...
Fish Agent V0.1 3BFish Agent V0.1 3B是一个开创性的语音转语音模型,能够以前所未有的精确度捕捉和生成环境音频信息。该模型采用了无语义标记架构,消除了传统... -
 hertz-devhertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术...
hertz-devhertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术... -
 OuteTTS-0.1-350MOuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合...
OuteTTS-0.1-350MOuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合... -
 Suno v4Suno v4是一个音乐创作平台,它通过提供更清晰的音频、更锐利的歌词和更动态的歌曲结构,帮助用户以更快的速度创作音乐。这个平台不仅提升了音乐创作的质...
Suno v4Suno v4是一个音乐创作平台,它通过提供更清晰的音频、更锐利的歌词和更动态的歌曲结构,帮助用户以更快的速度创作音乐。这个平台不仅提升了音乐创作的质... -
 SongCleanerSongCleaner是一个利用人工智能技术来清理歌曲中不适当词汇的平台,它允许用户上传MP3或WAV格式的音频文件,然后通过AI分析和编辑,生成适合...
SongCleanerSongCleaner是一个利用人工智能技术来清理歌曲中不适当词汇的平台,它允许用户上传MP3或WAV格式的音频文件,然后通过AI分析和编辑,生成适合... -
 AuralisAuralis是一个文本到语音(TTS)引擎,能够将文本快速转换为自然语音,支持语音克隆,并且处理速度极快,可以在几分钟内处理完整本小说。该产品以其高...
AuralisAuralis是一个文本到语音(TTS)引擎,能够将文本快速转换为自然语音,支持语音克隆,并且处理速度极快,可以在几分钟内处理完整本小说。该产品以其高... -
 ComfyUI-MMAudioComfyUI-MMAudio是一个基于ComfyUI的插件,它允许用户利用MMAudio模型进行音频处理。该插件的主要优点在于能够提供高质量的音频生...
ComfyUI-MMAudioComfyUI-MMAudio是一个基于ComfyUI的插件,它允许用户利用MMAudio模型进行音频处理。该插件的主要优点在于能够提供高质量的音频生... -
 OmniAudio-2.6BOmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个...
OmniAudio-2.6BOmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
