收集全球10,000⁺个好用的AI软件
-
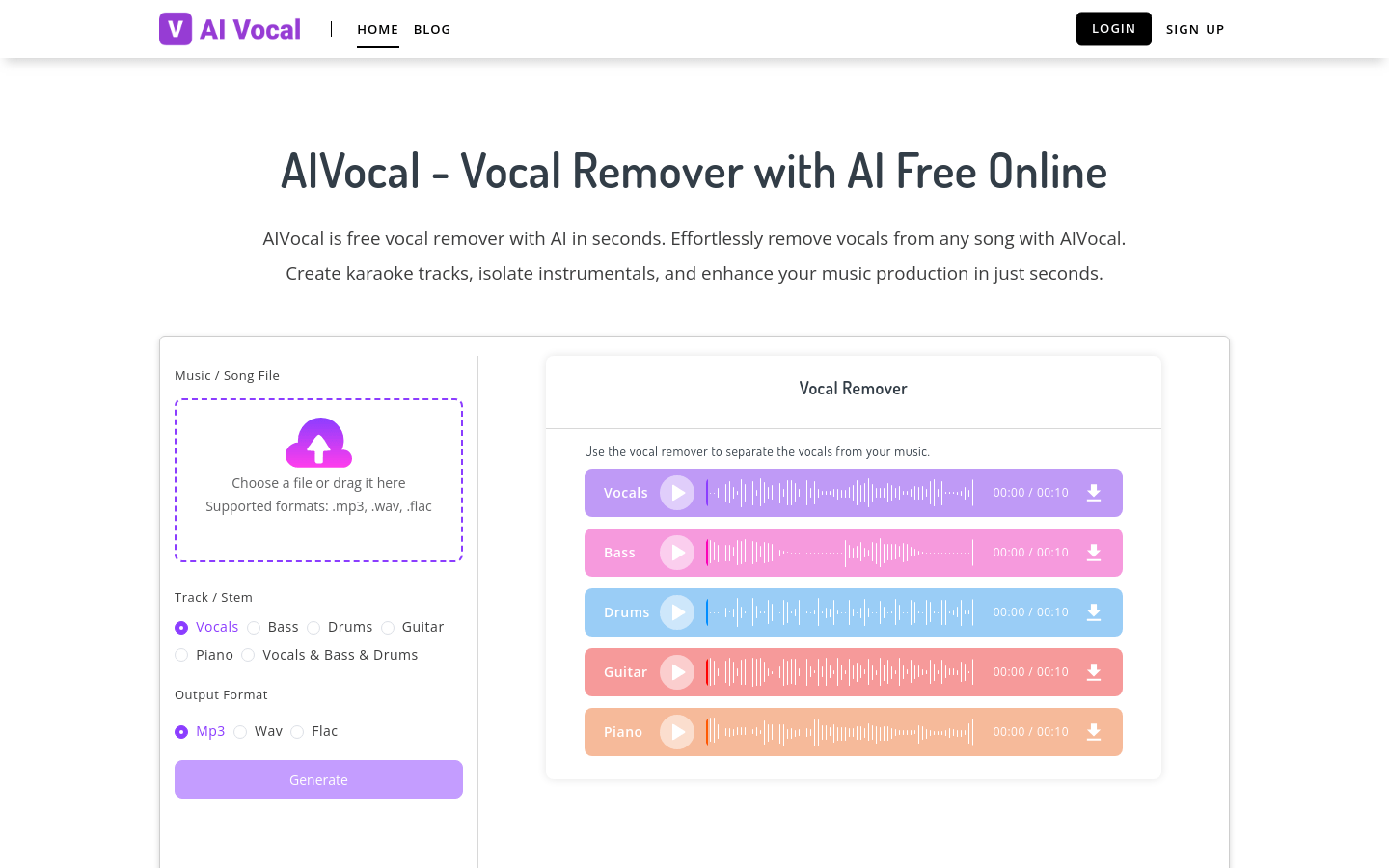 AIVocalAIVocal是一款基于人工智能技术的在线人声消除工具,它能够在短时间内从任何歌曲中去除人声,创建伴奏带、分离乐器音轨,并提升音乐制作效率。该产品以其...
AIVocalAIVocal是一款基于人工智能技术的在线人声消除工具,它能够在短时间内从任何歌曲中去除人声,创建伴奏带、分离乐器音轨,并提升音乐制作效率。该产品以其... -
 InspireMusicInspireMusic 是一个专注于音乐、歌曲和音频生成的 AIGC 工具包和模型框架,采用 PyTorch 开发。它通过音频标记化和解码过程,结合...
InspireMusicInspireMusic 是一个专注于音乐、歌曲和音频生成的 AIGC 工具包和模型框架,采用 PyTorch 开发。它通过音频标记化和解码过程,结合... -
 UniFabUniFab 是一款强大的 AI 助力的视频音频增强工具。它利用先进的超分辨率技术,能够将视频分辨率提升至 8K/16K,同时将 SDR 转换为 HD...
UniFabUniFab 是一款强大的 AI 助力的视频音频增强工具。它利用先进的超分辨率技术,能够将视频分辨率提升至 8K/16K,同时将 SDR 转换为 HD... -
 Fineshare SonixTwSonixTw AI Voice Cloning 是一款高质量的在线人工智能语音克隆产品,通过一次录音即可实现克隆,保留细腻的情感和音调。您可以为自己...
Fineshare SonixTwSonixTw AI Voice Cloning 是一款高质量的在线人工智能语音克隆产品,通过一次录音即可实现克隆,保留细腻的情感和音调。您可以为自己... -
 Easy Voice ToolkitEasy Voice Toolkit是一个基于开源语音项目的AI语音工具箱,提供包括语音模型训练在内的多种自动化音频工具。该工具箱能够无缝集成,形成完...
Easy Voice ToolkitEasy Voice Toolkit是一个基于开源语音项目的AI语音工具箱,提供包括语音模型训练在内的多种自动化音频工具。该工具箱能够无缝集成,形成完... -
 Universal-2Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复...
Universal-2Universal-2是AssemblyAI推出的最新语音识别模型,它在准确度和精确度上超越了前一代Universal-1,能够更好地捕捉人类语言的复... -
 Fish Agent V0.1 3BFish Agent V0.1 3B是一个开创性的语音转语音模型,能够以前所未有的精确度捕捉和生成环境音频信息。该模型采用了无语义标记架构,消除了传统...
Fish Agent V0.1 3BFish Agent V0.1 3B是一个开创性的语音转语音模型,能够以前所未有的精确度捕捉和生成环境音频信息。该模型采用了无语义标记架构,消除了传统... -
 hertz-devhertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术...
hertz-devhertz-dev是Standard Intelligence开源的全双工、仅音频的变换器基础模型,拥有85亿参数。该模型代表了可扩展的跨模态学习技术... -
 OuteTTS-0.1-350MOuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合...
OuteTTS-0.1-350MOuteTTS-0.1-350M是一款基于纯语言模型的文本到语音合成技术,它不需要外部适配器或复杂架构,通过精心设计的提示和音频标记实现高质量的语音合... -
 AuralisAuralis是一个文本到语音(TTS)引擎,能够将文本快速转换为自然语音,支持语音克隆,并且处理速度极快,可以在几分钟内处理完整本小说。该产品以其高...
AuralisAuralis是一个文本到语音(TTS)引擎,能够将文本快速转换为自然语音,支持语音克隆,并且处理速度极快,可以在几分钟内处理完整本小说。该产品以其高... -
 OmniAudio-2.6BOmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个...
OmniAudio-2.6BOmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个... -
 DevMind AIDevMind AI旨在无缝整合文本、图像、视频、音频和代码等多种模型的推理能力,帮助您像专业人士一样进行开发!DevMind AI通过AI功能增强您...
DevMind AIDevMind AI旨在无缝整合文本、图像、视频、音频和代码等多种模型的推理能力,帮助您像专业人士一样进行开发!DevMind AI通过AI功能增强您...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
