vision-parse
vision-parse官网入口
vision-parse登录网址
PDF解析
Markdown转换
文档处理
视觉语言模型
自动化
AI办公应用
AI文档处理
vision-parse是什么,是做什么的AI工具软件?
vision-parse是一个利用视觉语言模型(Vision LLMs)将PDF文档解析为格式化良好的Markdown内容的工具。它支持多种模型,包括OpenAI、LLama和Gemini等,能够智能识别和提取文本及表格,并保持文档的层级结构、样式和缩进。该工具的主要优点包括高精度的内容提取、格式保持、支持多模型以及本地模型托管,适用于需要高效文档处理的用户。
需求人群:
"目标受众为需要高效处理文档内容的用户,如数据分析师、研究人员和开发者。该工具适合他们,因为它可以快速准确地从PDF中提取信息,并转换为易于编辑和分享的Markdown格式。"
使用场景示例:
研究人员使用vision-parse将学术论文PDF转换为Markdown格式,以便在GitHub上分享和讨论。
数据分析师利用该工具从财务报告PDF中提取表格数据,进行进一步的数据分析。
开发者使用vision-parse将技术文档转换为Markdown,发布在文档网站上,提高文档的可读性和访问性。
产品特色:
智能内容提取:识别和提取文本和表格。
内容格式化:保持文档的层级结构和样式。
多模型支持:支持OpenAI、Google Gemini和Ollama等模型。
PDF文档支持:处理多页PDF文档,转换为字节64编码图像。
本地模型托管:支持使用Ollama进行安全和离线文档处理。
高精度提取:通过调整参数实现详细内容提取。
易于使用:只需几行代码即可实现PDF到Markdown的转换。
使用教程:
1. 安装Python环境(版本>=3.9)。
2. 使用pip安装vision-parse包:`pip install vision-parse`。
3. 根据需要安装OpenAI或Gemini的可选依赖。
4. 导入VisionParser类,并创建实例,设置模型名称和其他参数。
5. 使用VisionParser实例的convert_pdf方法,传入PDF文件路径。
6. 遍历返回的Markdown页面,处理每一页的内容。
7. 根据需要,可以设置PDFPageConfig来自定义PDF处理设置。
-
 PK
PK vision-parse VS Intellecs.AI
vision-parse VS Intellecs.AIvision-parse:vision-parse是一个利用视觉语言模型(Vision LLMs)将PDF文档解析为格式化良好的Markdown内容的工具。它支持多种模型,包括OpenAI、LLama和Gemini等,能够智能识别和提取文本及表格,并保持文档的层级结构、样式和缩进。该工具的主要优点包括高精度的内容提取、格式保持、支持多模型以及本地模型托管,适用于需要高效文档处理的用户。 ...
Intellecs.AI:Intellecs.AI 是一款简化信息获取的工具,提供准确的摘要和智能提问功能,最大限度地提高工作效率和学习流程。快速查找和定位 PDF 文件中的信息,轻松提问并获得准确的答案。通过 Intellecs.AI,告别信息过载,轻松掌握任何文档的要点。 ...
-
PK
 vision-parse VS Gamma
vision-parse VS Gammavision-parse:vision-parse是一个利用视觉语言模型(Vision LLMs)将PDF文档解析为格式化良好的Markdown内容的工具。它支持多种模型,包括OpenAI、LLama和Gemini等,能够智能识别和提取文本及表格,并保持文档的层级结构、样式和缩进。该工具的主要优点包括高精度的内容提取、格式保持、支持多模型以及本地模型托管,适用于需要高效文档处理的用户。 ...
Gamma:Gamma App是一种新型的内容呈现方式,通过AI技术帮助用户创造美观、引人入胜的演示文稿和网页,无需繁琐的格式和设计工作。Gamma App提供一键模板和可视化编辑功能,用户可以快速生成演示文稿、文档和网页,并进行个性化定制。Gamma App支持多种功能,包括生成精美的设计、提供多种样式选择、实时呈现、嵌入各种媒体内容等。用户可以在任何设备上浏览和分享创作的内容。Gamma App适用于各种场景,例如企业演示、教育培训、个人创作等。免费试用。 ...
-
PK
 vision-parse VS Beautiful.ai
vision-parse VS Beautiful.aivision-parse:vision-parse是一个利用视觉语言模型(Vision LLMs)将PDF文档解析为格式化良好的Markdown内容的工具。它支持多种模型,包括OpenAI、LLama和Gemini等,能够智能识别和提取文本及表格,并保持文档的层级结构、样式和缩进。该工具的主要优点包括高精度的内容提取、格式保持、支持多模型以及本地模型托管,适用于需要高效文档处理的用户。 ...
Beautiful.ai:Beautiful.ai是一个演示软件,为团队提供最佳设计、保持品牌一致性以及全球协作的功能。它应用先进的AI技术,使演示制作变得简单而美观。用户只需添加内容,Beautiful.ai会自动适应并应用出色的设计规则。不再需要在深夜调整文本和图片大小。每一个选择都能节省时间并带来出色的设计。 ...
-
PK
 vision-parse VS DesignerBot by Beautiful.ai
vision-parse VS DesignerBot by Beautiful.aivision-parse:vision-parse是一个利用视觉语言模型(Vision LLMs)将PDF文档解析为格式化良好的Markdown内容的工具。它支持多种模型,包括OpenAI、LLama和Gemini等,能够智能识别和提取文本及表格,并保持文档的层级结构、样式和缩进。该工具的主要优点包括高精度的内容提取、格式保持、支持多模型以及本地模型托管,适用于需要高效文档处理的用户。 ...
DesignerBot by Beautiful.ai:Beautiful.ai是一个免费的演示文稿制作工具,通过其设计AI功能,您可以在几分钟内将简单的演示文稿转变为精美的作品。它拥有数百个智能幻灯片,使您能够轻松有意义地表达想法,无需花费时间学习高级设计技巧。您只需添加内容,Beautiful.ai就会自动根据您的内容创建出演示文稿。您可以轻松编辑幻灯片,进行个性化的定制,以确保每个演示文稿与您的品牌一致。Beautiful.ai还提供了丰富的媒体库,包含数百万免费的高质量照片、视频和图标,帮助您制作引人注目的演示文稿。它还提供了AI演示文稿制作工具,可快速生成完整的演示文稿草稿,从而加快您的工作效率。 ...
-
PK
 vision-parse VS Decktopus AI
vision-parse VS Decktopus AIvision-parse:vision-parse是一个利用视觉语言模型(Vision LLMs)将PDF文档解析为格式化良好的Markdown内容的工具。它支持多种模型,包括OpenAI、LLama和Gemini等,能够智能识别和提取文本及表格,并保持文档的层级结构、样式和缩进。该工具的主要优点包括高精度的内容提取、格式保持、支持多模型以及本地模型托管,适用于需要高效文档处理的用户。 ...
Decktopus AI:Decktopus AI是一款AI演示文稿制作工具,能够在几秒钟内创建出令人惊叹的演示文稿。您只需输入演示文稿标题,即可获得完整的演示文稿。 ...
-
PK
 vision-parse VS SlidesAI
vision-parse VS SlidesAIvision-parse:vision-parse是一个利用视觉语言模型(Vision LLMs)将PDF文档解析为格式化良好的Markdown内容的工具。它支持多种模型,包括OpenAI、LLama和Gemini等,能够智能识别和提取文本及表格,并保持文档的层级结构、样式和缩进。该工具的主要优点包括高精度的内容提取、格式保持、支持多模型以及本地模型托管,适用于需要高效文档处理的用户。 ...
SlidesAI:SlidesAI是一款AI辅助文本转演示文稿工具,可以从任何文本生成摘要和演示文稿。它可以在几秒钟内自动创建专业、吸引人的演示文稿,让你告别繁琐、手动的幻灯片制作。 ...
-
PK
 vision-parse VS Presentations.ai
vision-parse VS Presentations.aivision-parse:vision-parse是一个利用视觉语言模型(Vision LLMs)将PDF文档解析为格式化良好的Markdown内容的工具。它支持多种模型,包括OpenAI、LLama和Gemini等,能够智能识别和提取文本及表格,并保持文档的层级结构、样式和缩进。该工具的主要优点包括高精度的内容提取、格式保持、支持多模型以及本地模型托管,适用于需要高效文档处理的用户。 ...
Presentations.ai:Presentations.AI是一款基于人工智能的演示文稿应用,帮助用户轻松构建漂亮的演示文稿。通过输入提示,使用AI在几秒钟内从零开始生成整个PPT演示文稿。试试免费创建一个吧! ...
-
PK
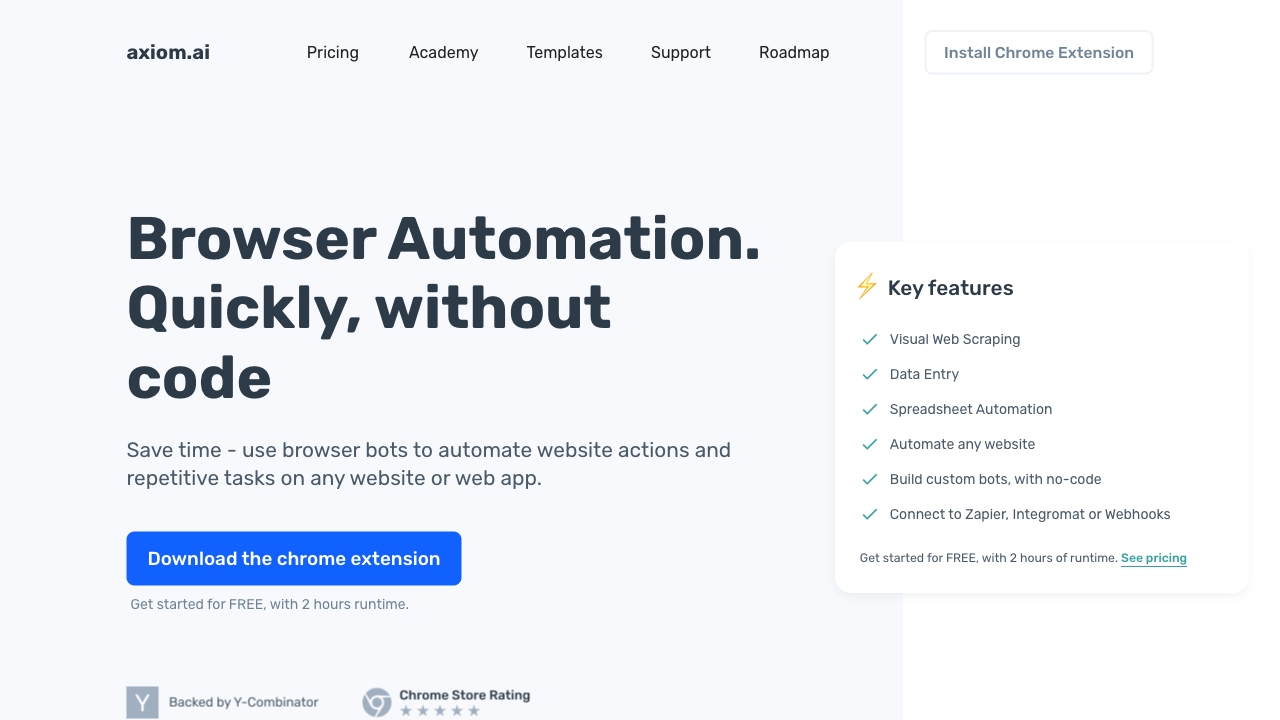 vision-parse VS Axiom
vision-parse VS Axiomvision-parse:vision-parse是一个利用视觉语言模型(Vision LLMs)将PDF文档解析为格式化良好的Markdown内容的工具。它支持多种模型,包括OpenAI、LLama和Gemini等,能够智能识别和提取文本及表格,并保持文档的层级结构、样式和缩进。该工具的主要优点包括高精度的内容提取、格式保持、支持多模型以及本地模型托管,适用于需要高效文档处理的用户。 ...
Axiom:Axiom.ai是一款无代码浏览器自动化插件,帮助用户快速简单地自动化网站操作和重复任务。它提供可视化网络抓取、数据录入、电子表格自动化等功能,用户可以在任何网站或Web应用程序上使用它。Axiom.ai支持自定义构建机器人,无需编码。同时,它还可以与Zapier、Integromat或Webhooks进行连接。您可以免费使用2小时的运行时间,详情请查看定价页面。 ...
-
PK
 vision-parse VS SlidesGPT
vision-parse VS SlidesGPTvision-parse:vision-parse是一个利用视觉语言模型(Vision LLMs)将PDF文档解析为格式化良好的Markdown内容的工具。它支持多种模型,包括OpenAI、LLama和Gemini等,能够智能识别和提取文本及表格,并保持文档的层级结构、样式和缩进。该工具的主要优点包括高精度的内容提取、格式保持、支持多模型以及本地模型托管,适用于需要高效文档处理的用户。 ...
SlidesGPT:SlidesGPT是一款强大的AI演示文稿生成工具。它能够帮助用户快速创建演示文稿,节省大量时间和精力。SlidesGPT支持与PowerPoint和Google Slides等平台兼容,提供丰富的主题和功能,用户可以根据需要定制演示文稿的样式和布局。无论是教育、商务还是其他领域,SlidesGPT都是您制作演示文稿的理想选择。 ...
-
PK
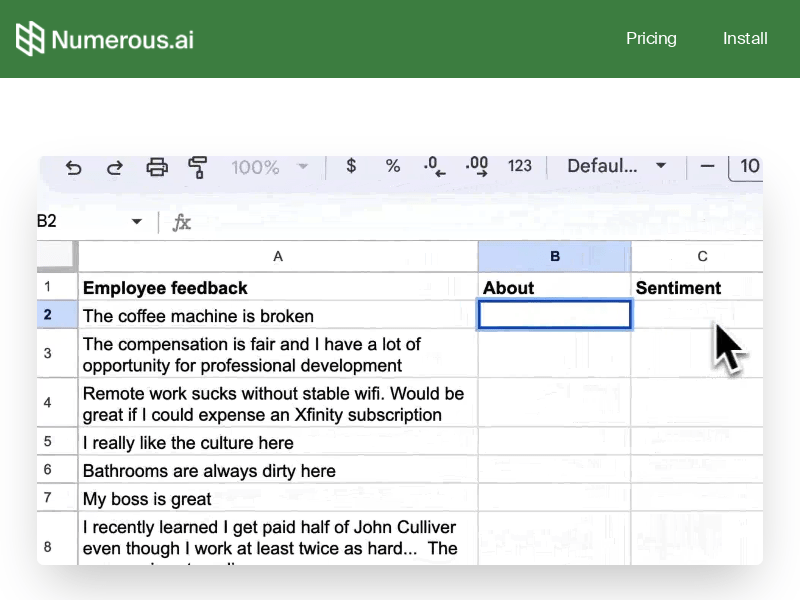 vision-parse VS numerous
vision-parse VS numerousvision-parse:vision-parse是一个利用视觉语言模型(Vision LLMs)将PDF文档解析为格式化良好的Markdown内容的工具。它支持多种模型,包括OpenAI、LLama和Gemini等,能够智能识别和提取文本及表格,并保持文档的层级结构、样式和缩进。该工具的主要优点包括高精度的内容提取、格式保持、支持多模型以及本地模型托管,适用于需要高效文档处理的用户。 ...
numerous:Numerous.ai是一个AI助手表格插件,它将ChatGPT引入Google Sheets和Excel,可在单元格内使用ChatGPT进行文字生成、文本分类、公式生成等功能。用户可以通过=AI()函数调用ChatGPT,=INFER()函数教会Numerous执行重复任务,=WRITE()函数让ChatGPT代替用户进行文字创作。此外,Numerous还支持用简洁的语言生成复杂的公式,解释复杂公式的功能。用户可根据不同套餐选择购买,套餐包含ChatGPT的使用次数和公式生成次数。 ...
卓商AI整理了一些与 vision-parse 功能相似或可平替的站点应用,您可点击列表中的标题即可对比查看详细介绍。
上一个
Coda
相关AI工具集
-
Intellecs.AIIntellecs.AI 是一款简化信息获取的工具,提供准确的摘要和智能提问功能,最大限度地提高工作效率和学习流程。快速查找和定位 PDF 文件中的信...
-
GammaGamma App是一种新型的内容呈现方式,通过AI技术帮助用户创造美观、引人入胜的演示文稿和网页,无需繁琐的格式和设计工作。Gamma App提供一...
-
Beautiful.aiBeautiful.ai是一个演示软件,为团队提供最佳设计、保持品牌一致性以及全球协作的功能。它应用先进的AI技术,使演示制作变得简单而美观。用户只需...
-
DesignerBot by Beautiful.aiBeautiful.ai是一个免费的演示文稿制作工具,通过其设计AI功能,您可以在几分钟内将简单的演示文稿转变为精美的作品。它拥有数百个智能幻灯片,使...
-
Decktopus AIDecktopus AI是一款AI演示文稿制作工具,能够在几秒钟内创建出令人惊叹的演示文稿。您只需输入演示文稿标题,即可获得完整的演示文稿。...
-
SlidesAISlidesAI是一款AI辅助文本转演示文稿工具,可以从任何文本生成摘要和演示文稿。它可以在几秒钟内自动创建专业、吸引人的演示文稿,让你告别繁琐、手动...
-
Presentations.aiPresentations.AI是一款基于人工智能的演示文稿应用,帮助用户轻松构建漂亮的演示文稿。通过输入提示,使用AI在几秒钟内从零开始生成整个PP...
-
AxiomAxiom.ai是一款无代码浏览器自动化插件,帮助用户快速简单地自动化网站操作和重复任务。它提供可视化网络抓取、数据录入、电子表格自动化等功能,用户可...
-
SlidesGPTSlidesGPT是一款强大的AI演示文稿生成工具。它能够帮助用户快速创建演示文稿,节省大量时间和精力。SlidesGPT支持与PowerPoint和...
-
numerousNumerous.ai是一个AI助手表格插件,它将ChatGPT引入Google Sheets和Excel,可在单元格内使用ChatGPT进行文字生成...
-
 MagicSlidesMagicSlides App是一款AI生成演示文稿的插件。它可以从任何文本生成演示文稿幻灯片,并自动概括文本内容,创建专业的演示文稿。用户只需输入主...
MagicSlidesMagicSlides App是一款AI生成演示文稿的插件。它可以从任何文本生成演示文稿幻灯片,并自动概括文本内容,创建专业的演示文稿。用户只需输入主... -
 MobileGPTMobileGPT是一款创新的个性化AI助手,通过集成OpenAI ChatGPT于WhatsApp中,为用户提供聊天、生成AI图片和文档等多种功能。...
MobileGPTMobileGPT是一款创新的个性化AI助手,通过集成OpenAI ChatGPT于WhatsApp中,为用户提供聊天、生成AI图片和文档等多种功能。...

卓商AI
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
最新收录
Spoke
Spoke是一款AI插件,为产品经理提供强大的、注重隐私的AI功能,能够在几秒钟内为用户提供上下文信息。它可以帮助全球快速增长的团队节省时间,创造上下...
LastMile AI
LastMile AI是一个AI开发平台,专为工程师而设计,可以用于原型开发和生成式AI应用的生产。它提供了一站式的多模态AI模型访问,包括语言模型(...
Dokkio
Dokkio是一款利用人工智能技术提供云文件协作的工具。它能帮助用户管理多个活动、搜索文档和文件、整理研究材料、组织内容库,并将所有文件和内容集中在一...

Engage Sphere AI
Engage Sphere是一个基于AI的员工参与度分析平台。它可以深入分析公司各个部门、团队和岗位的参与度,帮助管理者明确团队互动症结所在,并采取行...
Pikzels
Pikzels连接顶级人才和有远见的客户。我们促进协作,释放创意卓越。加入我们,获取来自各个领域的优秀专业人才。体验协作的力量,释放你的创意潜能。Pi...
Zoho Cliq
Zoho Cliq是一款专为提高企业工作效率而设计的在线即时通讯和协作平台。它将团队成员、对话和工作流集中在一个地方,实现无缝连接。主要功能包括:组织...
猜你喜欢
Spoke
Spoke是一款AI插件,为产品经理提供强大的、注重隐私的AI功能,能够在几秒钟内为用户提供上下文信息。它可以帮助全球快速增长的团队节省时间,创造上下...
LastMile AI
LastMile AI是一个AI开发平台,专为工程师而设计,可以用于原型开发和生成式AI应用的生产。它提供了一站式的多模态AI模型访问,包括语言模型(...
Dokkio
Dokkio是一款利用人工智能技术提供云文件协作的工具。它能帮助用户管理多个活动、搜索文档和文件、整理研究材料、组织内容库,并将所有文件和内容集中在一...
Engage Sphere AI
Engage Sphere是一个基于AI的员工参与度分析平台。它可以深入分析公司各个部门、团队和岗位的参与度,帮助管理者明确团队互动症结所在,并采取行...
Pikzels
Pikzels连接顶级人才和有远见的客户。我们促进协作,释放创意卓越。加入我们,获取来自各个领域的优秀专业人才。体验协作的力量,释放你的创意潜能。Pi...
Zoho Cliq
Zoho Cliq是一款专为提高企业工作效率而设计的在线即时通讯和协作平台。它将团队成员、对话和工作流集中在一个地方,实现无缝连接。主要功能包括:组织...
最新文章
1
2
3
4
5
6
7
8
9
10
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
