收集全球10,000⁺个好用的AI软件
-
 Stable Audio OpenStable Audio Open是一个开源的文本到音频模型,专为生成短音频样本、音效和制作元素而优化。它允许用户通过简单的文本提示生成高达47秒的高...
Stable Audio OpenStable Audio Open是一个开源的文本到音频模型,专为生成短音频样本、音效和制作元素而优化。它允许用户通过简单的文本提示生成高达47秒的高... -
 Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文...
Stable Audio Open 1.0Stable Audio Open 1.0是一个利用自编码器、基于T5的文本嵌入和基于变压器的扩散模型来生成长达47秒的立体声音频的AI模型。它通过文... -
 AudioLCMAudioLCM是一个基于PyTorch实现的文本到音频生成模型,它通过潜在一致性模型来生成高质量且高效的音频。该模型由Huadai Liu等人开发,...
AudioLCMAudioLCM是一个基于PyTorch实现的文本到音频生成模型,它通过潜在一致性模型来生成高质量且高效的音频。该模型由Huadai Liu等人开发,... -
 ElevenLabs 文本转音效APIElevenLabs的文本转音效API允许用户根据简短的文本描述生成高质量的音效,这些音效可以应用于游戏开发、音乐制作应用等多种场景。该API利用先进...
ElevenLabs 文本转音效APIElevenLabs的文本转音效API允许用户根据简短的文本描述生成高质量的音效,这些音效可以应用于游戏开发、音乐制作应用等多种场景。该API利用先进... -
 AudioSealAudioSeal 是一种用于AI生成语音音频的本地化水印技术,具有最先进的鲁棒性和极快的检测速度。它通过联合训练一个嵌入水印的生成器和一个检测器,即...
AudioSealAudioSeal 是一种用于AI生成语音音频的本地化水印技术,具有最先进的鲁棒性和极快的检测速度。它通过联合训练一个嵌入水印的生成器和一个检测器,即... -
 JASCOJASCO是一个结合了符号和基于音频的条件的文本到音乐生成模型,它能够根据全局文本描述和细粒度的局部控制生成高质量的音乐样本。JASCO基于流匹配建模...
JASCOJASCO是一个结合了符号和基于音频的条件的文本到音乐生成模型,它能够根据全局文本描述和细粒度的局部控制生成高质量的音乐样本。JASCO基于流匹配建模... -
 Resona V2AResona V2A是一款AI驱动的视频到音频生成技术产品,它能够仅通过视频数据自动生成与场景、动画或电影完美匹配的声音设计、效果、拟音和环境音。该技...
Resona V2AResona V2A是一款AI驱动的视频到音频生成技术产品,它能够仅通过视频数据自动生成与场景、动画或电影完美匹配的声音设计、效果、拟音和环境音。该技... -
 GenAUGenAU是一个由Snap Research开发的音频生成模型,它通过AutoCap自动字幕生成模型和GenAu音频生成架构,显著提升了音频生成的质量...
GenAUGenAU是一个由Snap Research开发的音频生成模型,它通过AutoCap自动字幕生成模型和GenAu音频生成架构,显著提升了音频生成的质量... -
 vta-ldmvta-ldm是一个专注于视频到音频生成的深度学习模型,能够根据视频内容生成语义和时间上与视频输入对齐的音频内容。它代表了视频生成领域的一个新突破,特...
vta-ldmvta-ldm是一个专注于视频到音频生成的深度学习模型,能够根据视频内容生成语义和时间上与视频输入对齐的音频内容。它代表了视频生成领域的一个新突破,特... -
 Stable Audio Open demoStable Audio Open 是一个能够从文本提示生成长达47秒的立体声音频的技术。它包含三个主要组件:一个将波形压缩到可管理序列长度的自编码器...
Stable Audio Open demoStable Audio Open 是一个能够从文本提示生成长达47秒的立体声音频的技术。它包含三个主要组件:一个将波形压缩到可管理序列长度的自编码器... -
 MaskVATMaskVAT是一种视频到音频(V2A)生成模型,它利用视频的视觉特征来生成与场景匹配的逼真声音。该模型特别强调声音的起始点与视觉动作的同步性,以避免...
MaskVATMaskVAT是一种视频到音频(V2A)生成模型,它利用视频的视觉特征来生成与场景匹配的逼真声音。该模型特别强调声音的起始点与视觉动作的同步性,以避免... -
 BarkBark是由Suno开发的基于Transformer的文本到音频模型,能够生成逼真的多语言语音以及其他类型的音频,如音乐、背景噪声和简单音效。它还支持...
BarkBark是由Suno开发的基于Transformer的文本到音频模型,能够生成逼真的多语言语音以及其他类型的音频,如音乐、背景噪声和简单音效。它还支持... -
 Loopy modelLoopy是一个端到端的音频驱动视频扩散模型,专门设计了跨剪辑和内部剪辑的时间模块以及音频到潜在表示模块,使模型能够利用数据中的长期运动信息来学习自然...
Loopy modelLoopy是一个端到端的音频驱动视频扩散模型,专门设计了跨剪辑和内部剪辑的时间模块以及音频到潜在表示模块,使模型能够利用数据中的长期运动信息来学习自然... -
 Stability AIStability AI是一个专注于生成式人工智能技术的公司,提供多种AI模型,包括文本到图像、视频、音频、3D和语言模型。这些模型能够处理复杂提示,...
Stability AIStability AI是一个专注于生成式人工智能技术的公司,提供多种AI模型,包括文本到图像、视频、音频、3D和语言模型。这些模型能够处理复杂提示,... -
 Seed-MusicSeed-Music 是一个音乐生成系统,它通过统一的框架支持生成具有表现力的多语言声乐音乐,允许精确到音符级别的调整,并提供将用户自己的声音融入音乐...
Seed-MusicSeed-Music 是一个音乐生成系统,它通过统一的框架支持生成具有表现力的多语言声乐音乐,允许精确到音符级别的调整,并提供将用户自己的声音融入音乐... -
 Aimusic soAI Music Generator Free Online是一个创新的音乐生成平台,利用先进的深度学习技术,将用户输入的文本转化为充满情感和高质量的...
Aimusic soAI Music Generator Free Online是一个创新的音乐生成平台,利用先进的深度学习技术,将用户输入的文本转化为充满情感和高质量的... -
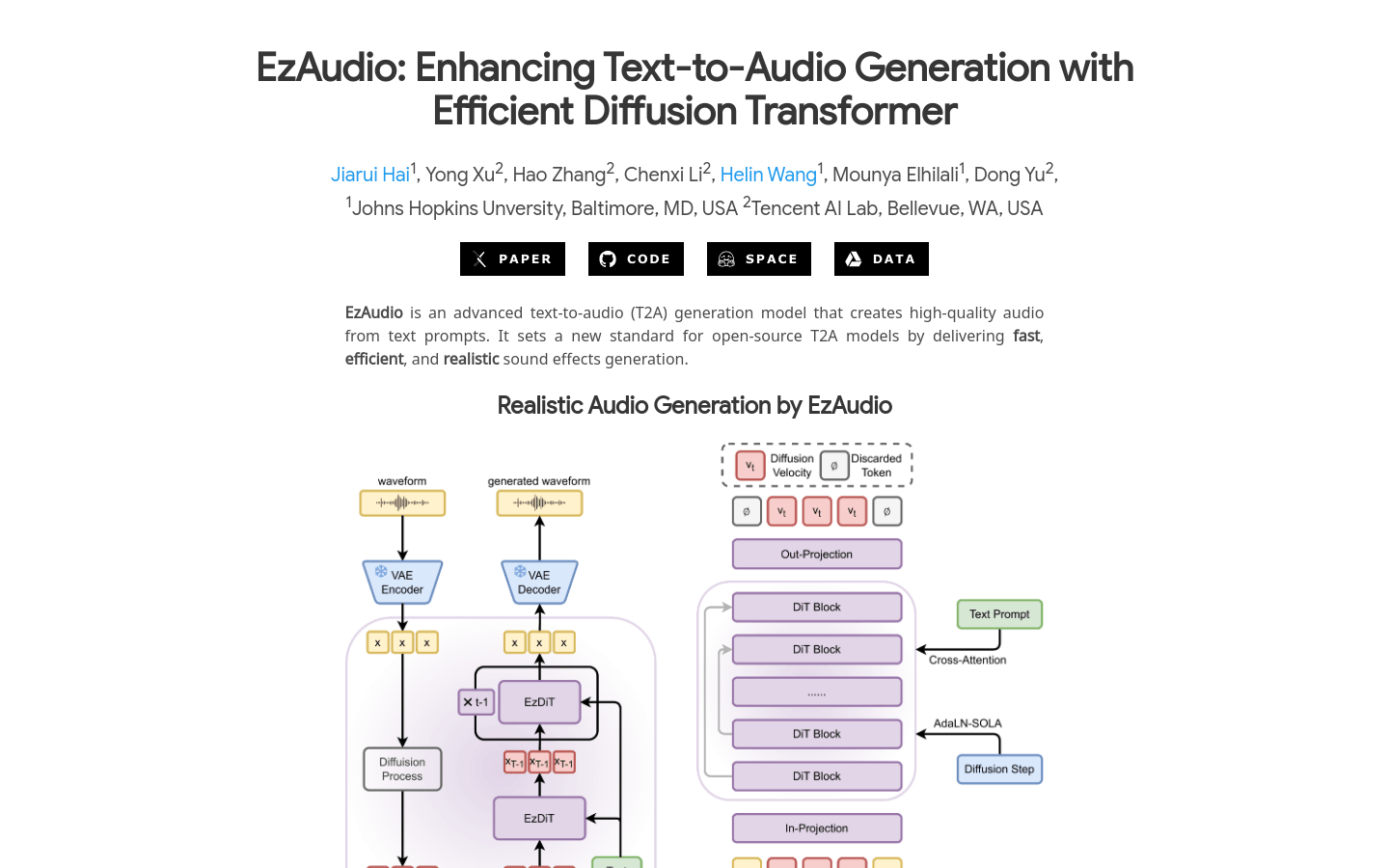 EzAudioEzAudio是一个先进的文本到音频(T2A)生成模型,它能够从文本提示中创建高质量的音频。它为开源T2A模型设定了新的标准,提供快速、高效和逼真的声...
EzAudioEzAudio是一个先进的文本到音频(T2A)生成模型,它能够从文本提示中创建高质量的音频。它为开源T2A模型设定了新的标准,提供快速、高效和逼真的声... -
 PDF2AudioPDF2Audio是一个利用OpenAI的GPT模型将PDF文档转换成音频内容的工具。它能够将文本生成和文本到语音转换技术结合起来,为用户提供一个可以...
PDF2AudioPDF2Audio是一个利用OpenAI的GPT模型将PDF文档转换成音频内容的工具。它能够将文本生成和文本到语音转换技术结合起来,为用户提供一个可以... -
 SFX EngineSFX Engine是一个AI声音效果生成器,专为音频制作人、视频编辑和游戏开发者设计。它提供了一个平台,用户可以通过AI技术生成定制的声音效果,用于...
SFX EngineSFX Engine是一个AI声音效果生成器,专为音频制作人、视频编辑和游戏开发者设计。它提供了一个平台,用户可以通过AI技术生成定制的声音效果,用于... -
 AILIBRIAILIBRI是一个汇集了超过2000个AI神经网络工具的目录网站,涵盖了文本、图像、视频、音频等多个领域的工具。它为用户寻找合适的AI工具提供了极大...
AILIBRIAILIBRI是一个汇集了超过2000个AI神经网络工具的目录网站,涵盖了文本、图像、视频、音频等多个领域的工具。它为用户寻找合适的AI工具提供了极大...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
