收集全球10,000⁺个好用的AI软件
-
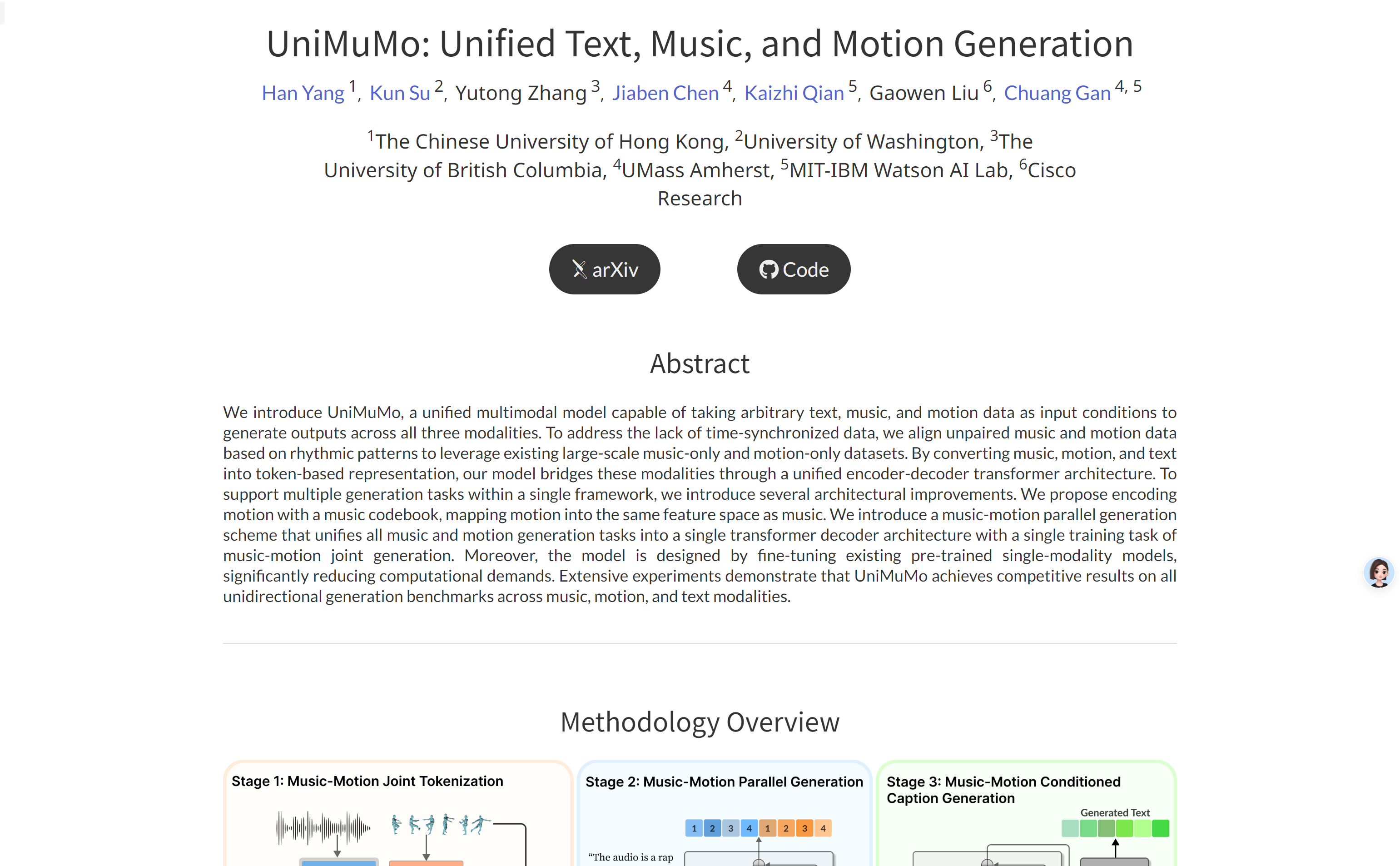 UniMuMoUniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示...
UniMuMoUniMuMo是一个多模态模型,能够将任意文本、音乐和动作数据作为输入条件,生成跨所有三种模态的输出。该模型通过将音乐、动作和文本转换为基于令牌的表示... -
 CLaMP 3CLaMP 3 是一种先进的音乐信息检索模型,通过对比学习对齐乐谱、演奏信号、音频录音与多语言文本的特征,支持跨模态和跨语言的音乐检索。它能够处理未对...
CLaMP 3CLaMP 3 是一种先进的音乐信息检索模型,通过对比学习对齐乐谱、演奏信号、音频录音与多语言文本的特征,支持跨模态和跨语言的音乐检索。它能够处理未对... -
 MagicAvatarMagicAvatar是一个多模态框架,能够将各种输入模式(文本、视频和音频)转换为运动信号,从而生成/动画化头像。它可以通过简单的文本提示创建头像,...
MagicAvatarMagicAvatar是一个多模态框架,能够将各种输入模式(文本、视频和音频)转换为运动信号,从而生成/动画化头像。它可以通过简单的文本提示创建头像,... -
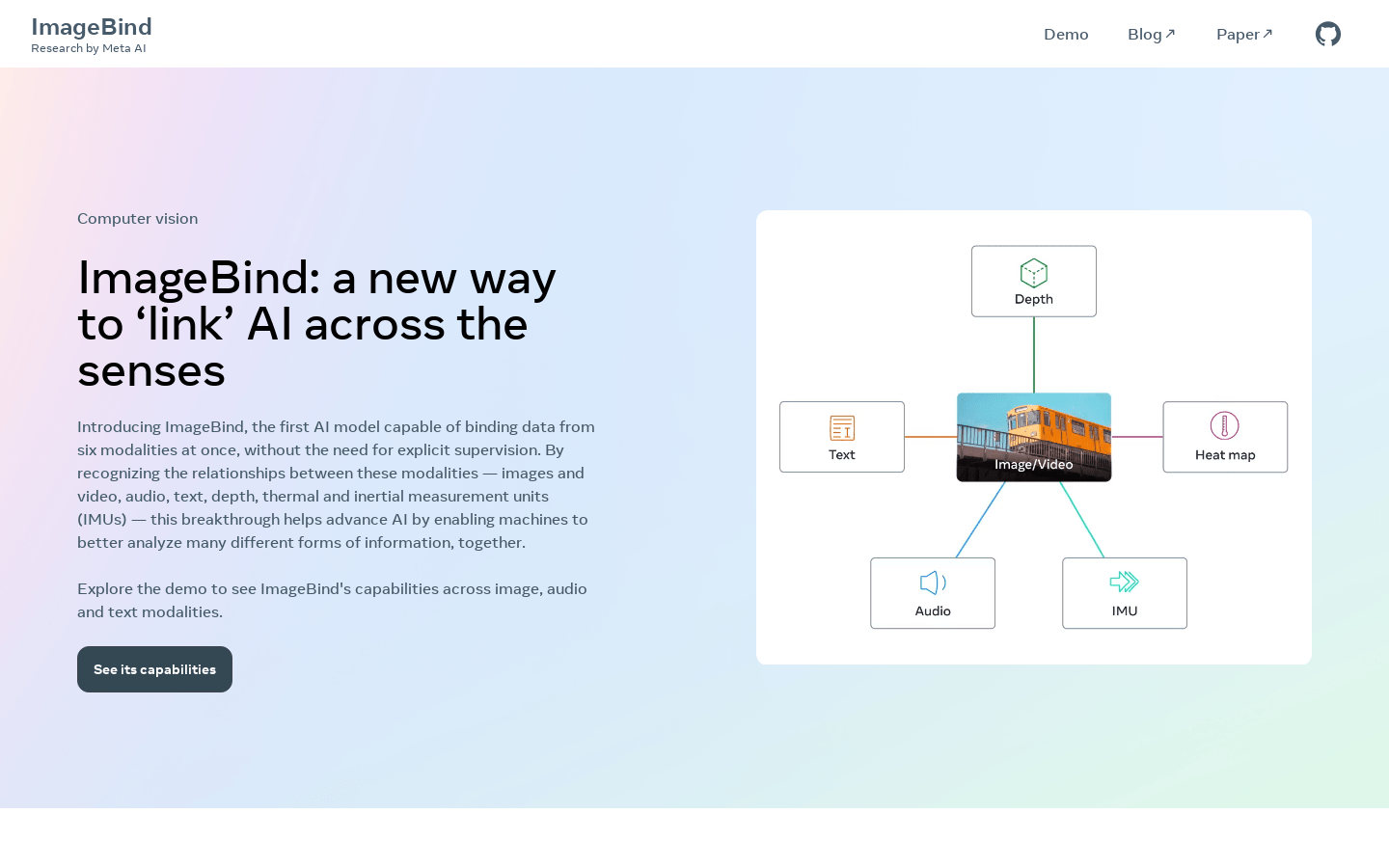 ImageBindImageBind是一种新的AI模型,能够同时绑定六种感官模态的数据,无需显式监督。通过识别这些模态之间的关系(图像和视频、音频、文本、深度、热成像和...
ImageBindImageBind是一种新的AI模型,能够同时绑定六种感官模态的数据,无需显式监督。通过识别这些模态之间的关系(图像和视频、音频、文本、深度、热成像和... -
 DevMind AIDevMind AI旨在无缝整合文本、图像、视频、音频和代码等多种模型的推理能力,帮助您像专业人士一样进行开发!DevMind AI通过AI功能增强您...
DevMind AIDevMind AI旨在无缝整合文本、图像、视频、音频和代码等多种模型的推理能力,帮助您像专业人士一样进行开发!DevMind AI通过AI功能增强您... -
 Unified-IO 2Unified-IO 2是一个统一的多模态生成模型,能够理解和生成图像、文本、音频和动作。它使用单个编码器-解码器Transformer模型,将不同模...
Unified-IO 2Unified-IO 2是一个统一的多模态生成模型,能够理解和生成图像、文本、音频和动作。它使用单个编码器-解码器Transformer模型,将不同模... -
 Mini-OmniMini-Omni是一个开源的多模态大型语言模型,能够实现实时的语音输入和流式音频输出的对话能力。它具备实时语音到语音的对话功能,无需额外的ASR或T...
Mini-OmniMini-Omni是一个开源的多模态大型语言模型,能够实现实时的语音输入和流式音频输出的对话能力。它具备实时语音到语音的对话功能,无需额外的ASR或T... -
 MMAudioMMAudio是一种多模态联合训练技术,旨在高质量的视频到音频合成。该技术能够根据视频和文本输入生成同步音频,适用于各种应用场景,如影视制作、游戏开发...
MMAudioMMAudio是一种多模态联合训练技术,旨在高质量的视频到音频合成。该技术能够根据视频和文本输入生成同步音频,适用于各种应用场景,如影视制作、游戏开发... -
 OmniAudio-2.6BOmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个...
OmniAudio-2.6BOmniAudio-2.6B是一个2.6B参数的多模态模型,能够无缝处理文本和音频输入。该模型结合了Gemma-2B、Whisper turbo和一个... -
 MILSMILS是一个由Facebook Research发布的开源项目,旨在展示大型语言模型(LLMs)在未经过任何训练的情况下,能够处理视觉和听觉任务的能...
MILSMILS是一个由Facebook Research发布的开源项目,旨在展示大型语言模型(LLMs)在未经过任何训练的情况下,能够处理视觉和听觉任务的能... -
 SpeechGPTSpeechGPT是一种多模态语言模型,具有内在的跨模态对话能力。它能够感知并生成多模态内容,遵循多模态人类指令。SpeechGPT-Gen是一种扩展...
SpeechGPTSpeechGPT是一种多模态语言模型,具有内在的跨模态对话能力。它能够感知并生成多模态内容,遵循多模态人类指令。SpeechGPT-Gen是一种扩展... -
 Any GPTAnyGPT是一个统一的多模态大型语言模型,利用离散表示进行各种模态的统一处理,包括语音、文本、图像和音乐。AnyGPT可以在不改变当前大型语言模型架...
Any GPTAnyGPT是一个统一的多模态大型语言模型,利用离散表示进行各种模态的统一处理,包括语音、文本、图像和音乐。AnyGPT可以在不改变当前大型语言模型架... -
 Gemini 1.5 FlashGemini 1.5 Flash是Google DeepMind团队推出的最新AI模型,它通过蒸馏过程从更大的1.5 Pro模型中提炼出核心知识和技能...
Gemini 1.5 FlashGemini 1.5 Flash是Google DeepMind团队推出的最新AI模型,它通过蒸馏过程从更大的1.5 Pro模型中提炼出核心知识和技能... -
 GPT4o.soGPT-4o是OpenAI的最新创新,代表了人工智能技术的前沿。它通过真正的多模态方法扩展了GPT-4的功能,包括文本、视觉和音频。GPT-4o以其快...
GPT4o.soGPT-4o是OpenAI的最新创新,代表了人工智能技术的前沿。它通过真正的多模态方法扩展了GPT-4的功能,包括文本、视觉和音频。GPT-4o以其快... -
 Real-time Voice AI AgentReal-time Voice AI Agent是一个高度灵活的实时语音交互模型,它能够在大约500毫秒内通过语音回答任何查询。该模型支持用户选择任何...
Real-time Voice AI AgentReal-time Voice AI Agent是一个高度灵活的实时语音交互模型,它能够在大约500毫秒内通过语音回答任何查询。该模型支持用户选择任何... -
 Llama3-s v0.2Llama3-s v0.2 是 Homebrew Computer Company 开发的多模态检查点,专注于提升语音理解能力。该模型通过早期融合语义...
Llama3-s v0.2Llama3-s v0.2 是 Homebrew Computer Company 开发的多模态检查点,专注于提升语音理解能力。该模型通过早期融合语义... -
Mini-OmniMini-Omni是一个开源的多模态大型语言模型,能够实现实时的语音输入和流式音频输出的对话能力。它具备实时语音到语音的对话功能,无需额外的ASR或T...
-
 LLaMA-OmniLLaMA-Omni是一个基于Llama-3.1-8B-Instruct构建的低延迟、高质量的端到端语音交互模型,旨在实现GPT-4o级别的语音能力。...
LLaMA-OmniLLaMA-Omni是一个基于Llama-3.1-8B-Instruct构建的低延迟、高质量的端到端语音交互模型,旨在实现GPT-4o级别的语音能力。... -
 EMOVAEMOVA(EMotionally Omni-present Voice Assistant)是一个多模态语言模型,它能够进行端到端的语音处理,同时保...
EMOVAEMOVA(EMotionally Omni-present Voice Assistant)是一个多模态语言模型,它能够进行端到端的语音处理,同时保... -
 LiveKit AgentsLiveKit Agents 是一个端到端框架,它使开发者能够构建能够通过语音、视频和数据通道与用户互动的智能多模态语音助手(AI代理)。它通过集成O...
LiveKit AgentsLiveKit Agents 是一个端到端框架,它使开发者能够构建能够通过语音、视频和数据通道与用户互动的智能多模态语音助手(AI代理)。它通过集成O...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
