上一篇
Baichuan-M1-14B是什么?一文让你看懂Baichuan-M1-14B的技术原理、主要功能、应用场景CogVideoX-2是什么?一文让你看懂CogVideoX-2的技术原理、主要功能、应用场景
来源:卓商AI
发布时间:2025-04-05
CogVideoX-2概述简介
CogVideoX-2是智谱 AI 推出的文本到视频生成模型,基于先进的 3D 变分自编码器(VAE),将视频数据压缩到原本的 2%,减少资源使用,同时确保视频帧之间的连贯流畅。 通过独特的 3D 旋转位置编码技术,视频在时间轴上能够自然流动,赋予画面生命力。模型结构、训练方法、数据工程全面更新,图生视频基础模型能力大幅度提升38%。生成更可控,支持画面主体进行大幅度运动,同时保持画面稳定性。指令遵从能力行业领先,能够理解和实现各种复杂prompt。能驾驭各种艺术风格,画面美感大幅提升支持 FP16、BF16、FP32、FP8 和 INT8 等多种推理精度。
CogVideoX-2的功能特色
文本到视频生成:CogVideoX-2能根据用户输入的文本描述生成高质量的视频内容,支持长达6秒、每秒8帧、分辨率为720×480的视频输出。
图生视频:可以将用户提供的静态图像转化为动态视频。为达到最佳效果,推荐上传比例为3:2的图片
高效显存利用:模型在FP16精度下推理仅需18GB显存,适合在资源有限的设备上运行。
多推理精度支持:支持FP16、BF16、INT8等多种推理精度,用户可以根据硬件条件选择合适的精度以优化性能。
灵活的二次开发:模型设计简洁,易于进行二次开发和定制,适合不同层次的开发者。
高质量视频生成:通过3D变分自编码器(3D VAE)和专家Transformer架构,CogVideoX-2能够生成连贯且高质量的视频。
低门槛提示词:用户可以使用简单的文本描述作为输入,模型能够理解并生成相应的视频内容。
CogVideoX-2的技术原理
3D 变分自编码器(3D VAE):CogVideoX-2 采用了 3D VAE 技术,通过三维卷积同时压缩视频的空间和时间维度,将视频数据压缩至原始大小的 2%,显著减少了计算资源的消耗。
专家 Transformer 架构:模型引入了专家 Transformer 架构,能深入解析编码后的视频数据,结合文本输入生成高质量、富有故事性的视频内容。架构通过 3D Full Attention 实现时空注意力建模,优化了文本和视频之间的对齐度。
3D 旋转位置编码(3D RoPE):为了更好地捕捉视频帧之间的时空关系,CogVideoX-2 使用了 3D RoPE 技术,分别对时间、空间坐标进行旋转位置编码,提升了模型在时间维度上的建模能力。
高质量数据驱动:智谱 AI 开发了高效的视频数据筛选方法,排除了低质量视频,确保训练数据的高标准和纯净度。构建了从图像字幕到视频字幕的生成管道,解决了视频数据普遍缺乏详尽文本描述的问题。
混合训练策略:CogVideoX-2 采用了图像与视频混合训练、渐进式分辨率训练以及高质量数据微调等策略,进一步提升了模型的生成能力和连贯性。
CogVideoX-2项目介绍
项目官网:BigModel
CogVideoX-2能做什么?
影视创作:影视制作人员可以用 CogVideoX-2 将剧本概念快速转化为可视化演示,直观评估剧情走向和场景设置是否合理。
广告与营销:品牌和广告公司可以通过 CogVideoX-2 根据文案直接生成多种风格的广告视频,节省制作成本的同时提高创意灵活性。
教育与培训:教育工作者可以用模型批量制作生动的教学视频,帮助学生更好地理解和掌握知识。
社交媒体与短视频制作:社交媒体博主和短视频创作者可以将文字创意快速转化为引人入胜的视频内容,吸引粉丝关注。
© 版权声明:本站所有原创文章版权均归卓商AI工具集及原创作者所有,未经允许任何个人、媒体、网站不得转载或以其他方式抄袭本站任何文章。
相关文章
-
 CHANGER是什么?一文让你看懂CHANGER的技术原理、主要功能、应用场景2025-04-05
CHANGER是什么?一文让你看懂CHANGER的技术原理、主要功能、应用场景2025-04-05 -
Kiroku是什么?一文让你看懂Kiroku的技术原理、主要功能、应用场景2025-04-05
-
Vision Search Assistant是什么?一文让你看懂Vision Search Assistant的技术原理、主要功能、应用场景2025-04-05
-
MVDrag3D是什么?一文让你看懂MVDrag3D的技术原理、主要功能、应用场景2025-04-05
-
Chonkie是什么?一文让你看懂Chonkie的技术原理、主要功能、应用场景2025-04-05
-
MSQA是什么?一文让你看懂MSQA的技术原理、主要功能、应用场景2025-04-05

卓商AI
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
最新发布
1
2
3
4
5
6
7
8
9
10
猜你喜欢

storymania ai story generator
与AI -Power的平台与Storymania进行工艺吸引人的故事,旨在协助各个级别的作家。在干净,无广告的环境中享受无缝的编辑和类型定制。在创纪录...
Notion Sites
Notion Sites 是一个简单易用的网站搭建工具,用户可以通过拖放式构建块快速创建个性化网站,无需编写复杂的HTML或代码。它提供了超过10,0...

Next.js
Next.js 是一个用于构建现代 React 应用程序的框架。它提供了许多功能和优势,包括服务器渲染、静态生成、热模块替换等。Next.js 的定价...
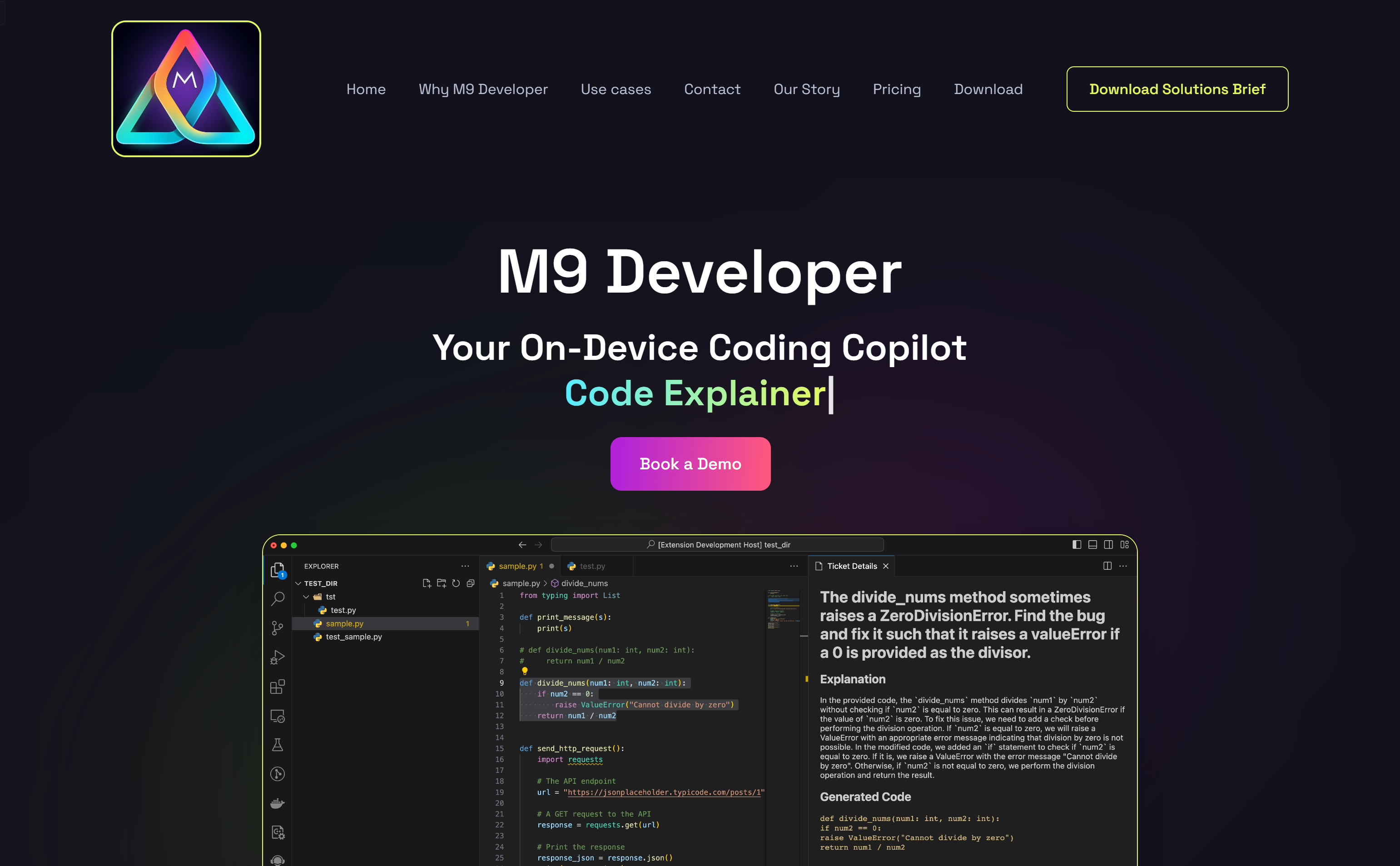
M9 Developer
M9 Developer是一款AI驱动的软件开发生命周期自动化工具,旨在通过自动化95%以上的开发任务来提高开发者的工作效率。该产品允许在现有的IDE...

Vapi
Vapi 是一个为开发者设计的语音 AI 代理平台,支持企业从初创公司到财富 500 强的各种需求。其灵活的 API 设计和多种语言支持使得它在电话运...
Grimo
Grimo 是一个高效的 AI 文本编辑器,结合最新的 AI 模型,如 DeepSeek R1 和 OpenAI GPT-4,致力于提升用户的写作体验...
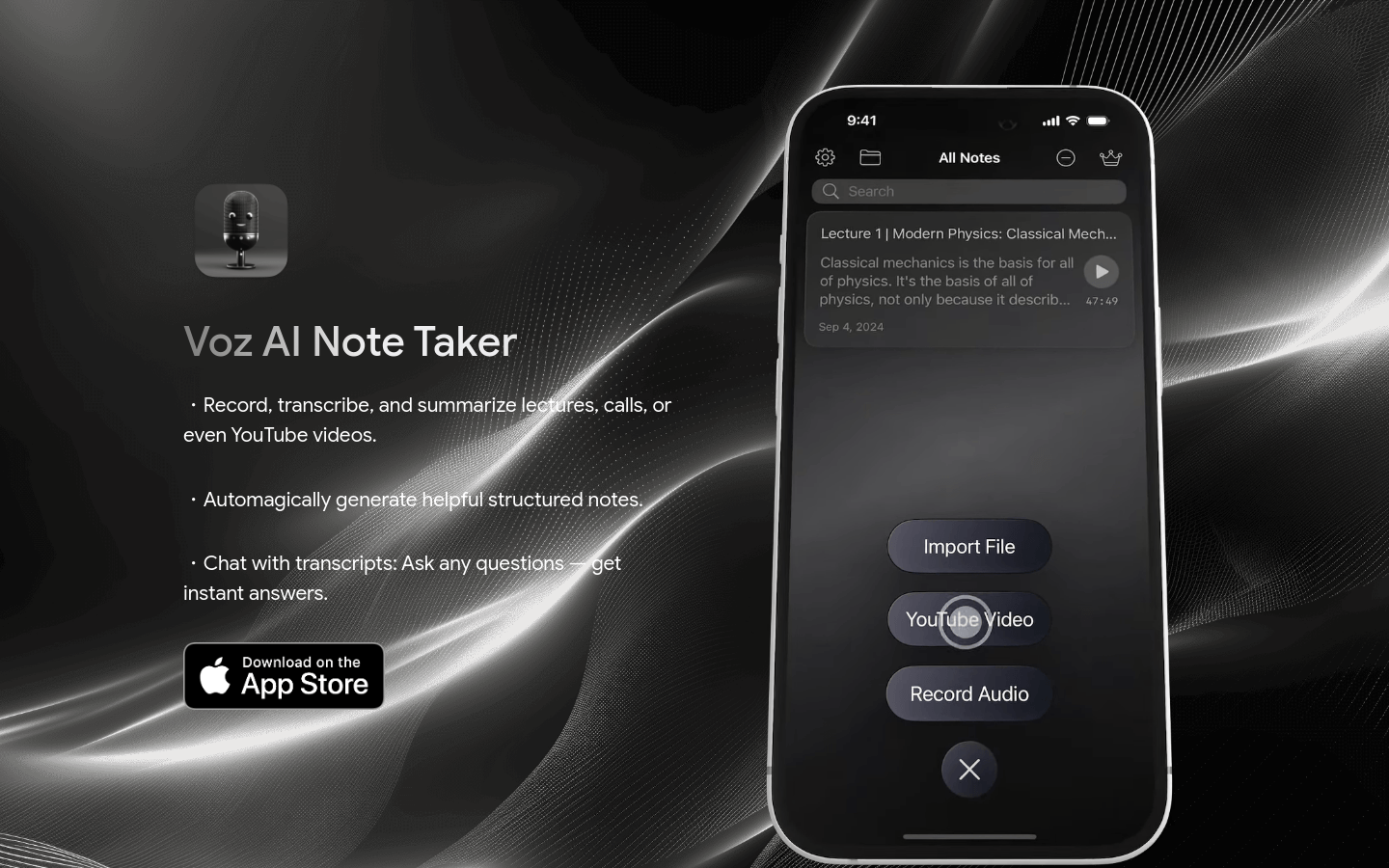
Voz AI Note Taker
Voz AI Note Taker是一个利用人工智能技术自动记录、转录和总结讲座、通话和视频内容的生产力工具。它通过自动化的方式生成结构化笔记,帮助用...

可灵 AI
可灵 AI 是一款集成了 AI 图像和视频创作功能的创意生产力平台。其主要优点在于快速生成多样风格的图片和高清视频,助力用户提升创作效率。产品定位于为...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
