收集全球10,000⁺个好用的AI软件
-
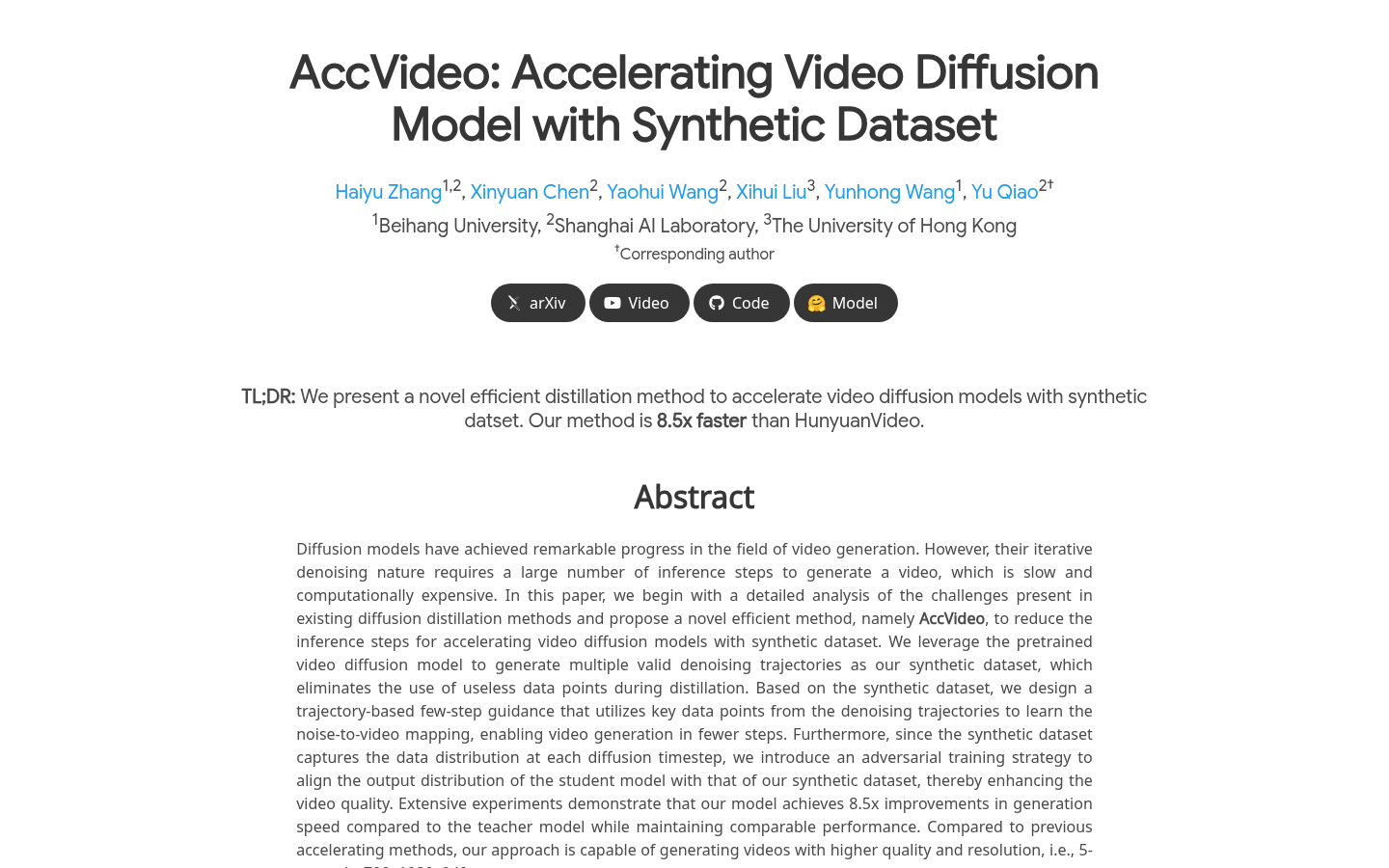 AccVideoAccVideo 是一种新颖的高效蒸馏方法,通过合成数据集加速视频扩散模型的推理速度。该模型能够在生成视频时实现 8.5 倍的速度提升,同时保持相似的...
AccVideoAccVideo 是一种新颖的高效蒸馏方法,通过合成数据集加速视频扩散模型的推理速度。该模型能够在生成视频时实现 8.5 倍的速度提升,同时保持相似的... -
 In-Context LoRA for Diffusion TransformersIn-Context LoRA是一种用于扩散变换器(DiTs)的微调技术,它通过结合图像而非仅仅文本,实现了在保持任务无关性的同时,对特定任务进行微调...
In-Context LoRA for Diffusion TransformersIn-Context LoRA是一种用于扩散变换器(DiTs)的微调技术,它通过结合图像而非仅仅文本,实现了在保持任务无关性的同时,对特定任务进行微调... -
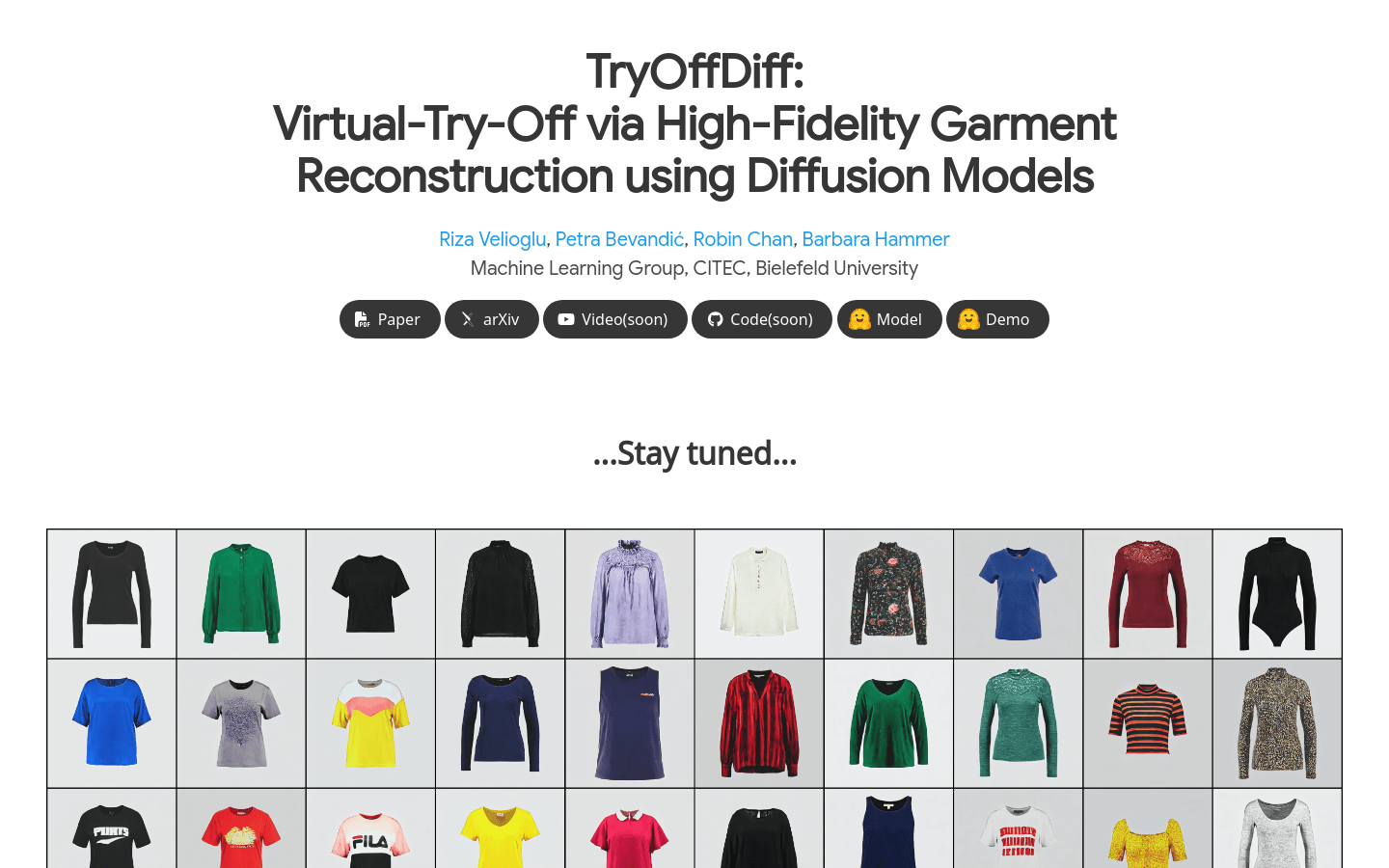 TryOffDiffTryOffDiff是一种基于扩散模型的高保真服装重建技术,用于从穿着个体的单张照片中生成标准化的服装图像。这项技术与传统的虚拟试穿不同,它旨在提取规...
TryOffDiffTryOffDiff是一种基于扩散模型的高保真服装重建技术,用于从穿着个体的单张照片中生成标准化的服装图像。这项技术与传统的虚拟试穿不同,它旨在提取规... -
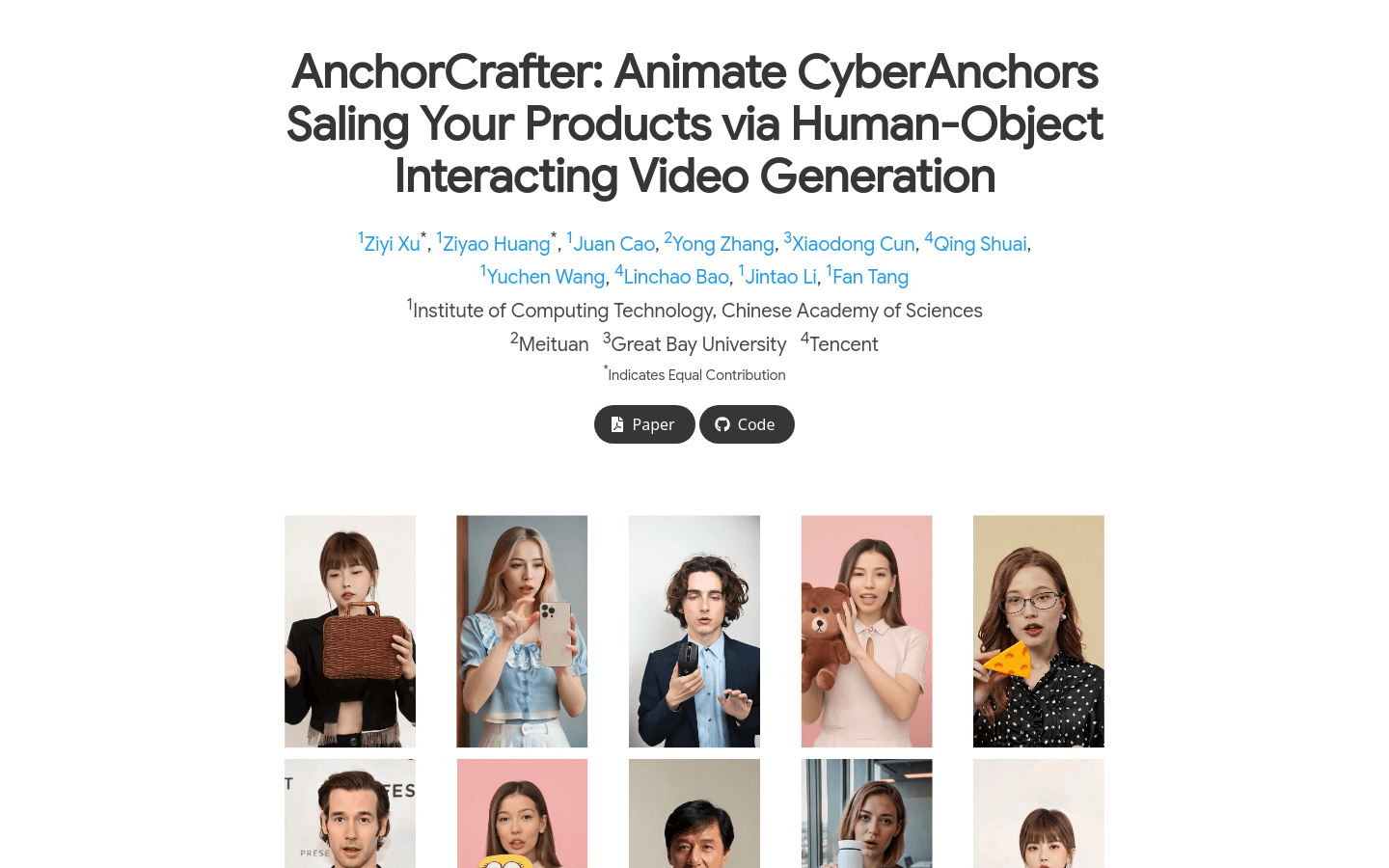 AnchorCrafterAnchorCrafter是一个创新的扩散模型系统,旨在生成包含目标人物和定制化对象的2D视频,通过人-物交互(HOI)的集成,实现高视觉保真度和可控...
AnchorCrafterAnchorCrafter是一个创新的扩散模型系统,旨在生成包含目标人物和定制化对象的2D视频,通过人-物交互(HOI)的集成,实现高视觉保真度和可控... -
 GameNGenGameNGen是一个完全由神经模型驱动的游戏引擎,能够实现与复杂环境的实时互动,并在长时间轨迹上保持高质量。它能够以每秒超过20帧的速度交互式模拟经...
GameNGenGameNGen是一个完全由神经模型驱动的游戏引擎,能够实现与复杂环境的实时互动,并在长时间轨迹上保持高质量。它能够以每秒超过20帧的速度交互式模拟经... -
 AI PhotoAI Photo是一款用户友好的文本转图片生成应用,可离线根据您的图像描述创建照片和艺术品。它采用稳定扩散技术,针对苹果芯片(M1和M2)进行了高度优...
AI PhotoAI Photo是一款用户友好的文本转图片生成应用,可离线根据您的图像描述创建照片和艺术品。它采用稳定扩散技术,针对苹果芯片(M1和M2)进行了高度优... -
 Stable Diffusion Model稳定扩散网络是一种先进的AI艺术生成平台,可让您在几秒钟内从任何文字输入中生成逼真的图像和可定制的头像。拥有超过1000万个提示可供选择,立即探索并生...
Stable Diffusion Model稳定扩散网络是一种先进的AI艺术生成平台,可让您在几秒钟内从任何文字输入中生成逼真的图像和可定制的头像。拥有超过1000万个提示可供选择,立即探索并生... -
 QR DiffusionQR Diffusion是一个免费的QR码艺术生成器,使用稳定扩散和ControlNet技术,在几秒钟内生成令人惊叹的艺术品般的QR码。它超越了传统Q...
QR DiffusionQR Diffusion是一个免费的QR码艺术生成器,使用稳定扩散和ControlNet技术,在几秒钟内生成令人惊叹的艺术品般的QR码。它超越了传统Q... -
 ThinkDiffusionThink Diffusion是一个稳定扩散的 AI 艺术实验室,提供全功能的托管工作空间,包括Automatic1111、ComfyUI、Foooc...
ThinkDiffusionThink Diffusion是一个稳定扩散的 AI 艺术实验室,提供全功能的托管工作空间,包括Automatic1111、ComfyUI、Foooc... -
 Stable Video Diffusion 1.1 Image-to-VideoStable Video Diffusion (SVD) 1.1 Image-to-Video 是一个扩散模型,通过将静止图像作为条件帧,生成相应的视...
Stable Video Diffusion 1.1 Image-to-VideoStable Video Diffusion (SVD) 1.1 Image-to-Video 是一个扩散模型,通过将静止图像作为条件帧,生成相应的视... -
 PIXARTPIXART-Σ是一个直接生成4K分辨率图像的扩散变换器模型,相较于前身PixArt-α,它提供了更高的图像保真度和与文本提示更好的对齐。PIXART...
PIXARTPIXART-Σ是一个直接生成4K分辨率图像的扩散变换器模型,相较于前身PixArt-α,它提供了更高的图像保真度和与文本提示更好的对齐。PIXART... -
 SLD (Self-correcting LLM-controlled Diffusion Models)SLD是一个自纠正的LLM控制的扩散模型框架,它通过集成检测器增强生成模型,以实现精确的文本到图像对齐。SLD框架支持图像生成和精细编辑,并且与任何图...
SLD (Self-correcting LLM-controlled Diffusion Models)SLD是一个自纠正的LLM控制的扩散模型框架,它通过集成检测器增强生成模型,以实现精确的文本到图像对齐。SLD框架支持图像生成和精细编辑,并且与任何图... -
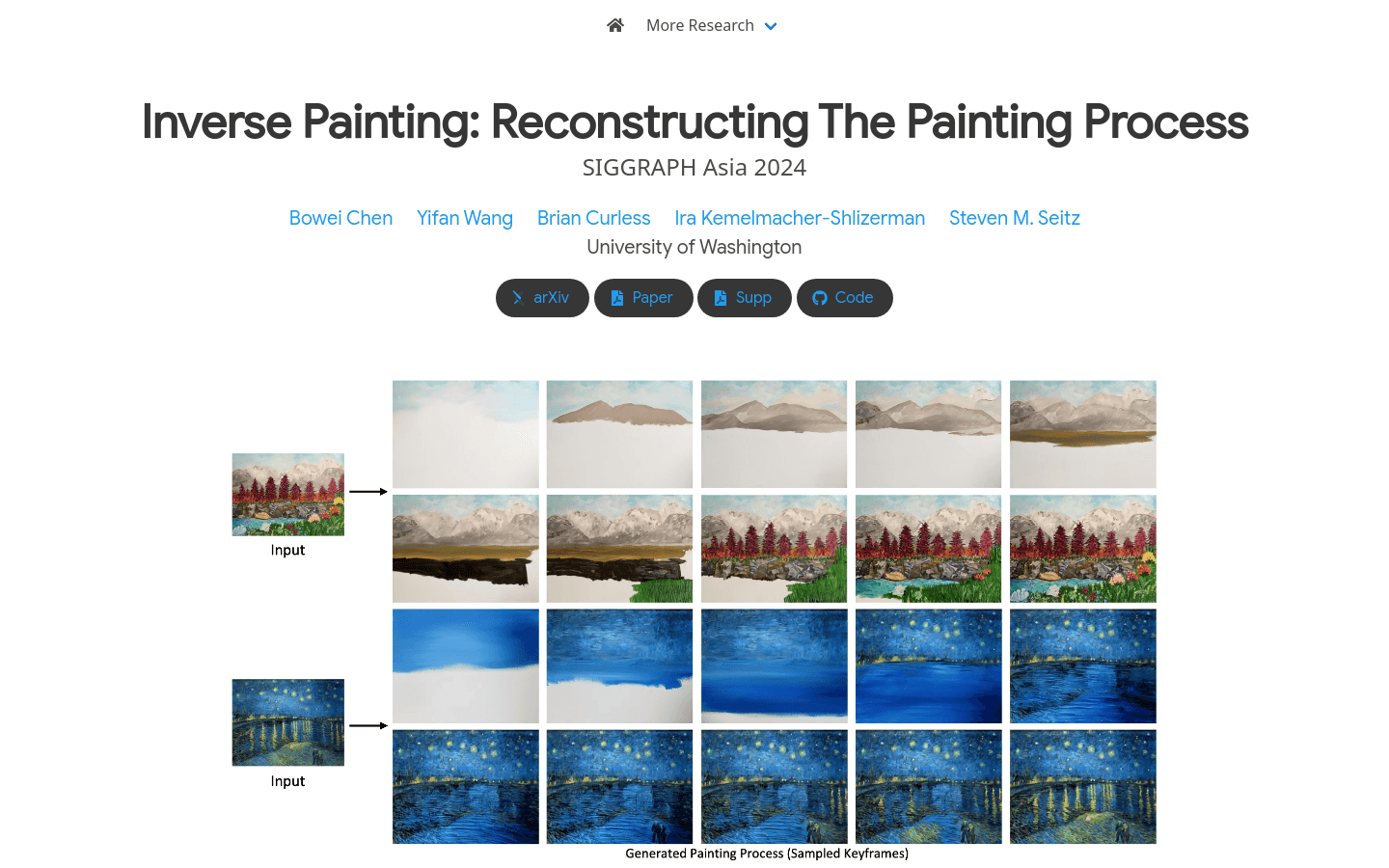 Inverse PaintingInverse Painting 是一种基于扩散模型的方法,能够从一幅目标画作生成绘画过程的时间流逝视频。该技术通过训练学习真实艺术家的绘画过程,能够...
Inverse PaintingInverse Painting 是一种基于扩散模型的方法,能够从一幅目标画作生成绘画过程的时间流逝视频。该技术通过训练学习真实艺术家的绘画过程,能够... -
 MakeAnythingMakeAnything 是一个基于扩散变换器的模型,专注于多领域程序化序列生成。该技术通过结合先进的扩散模型和变换器架构,能够生成高质量的、逐步的创...
MakeAnythingMakeAnything 是一个基于扩散变换器的模型,专注于多领域程序化序列生成。该技术通过结合先进的扩散模型和变换器架构,能够生成高质量的、逐步的创... -
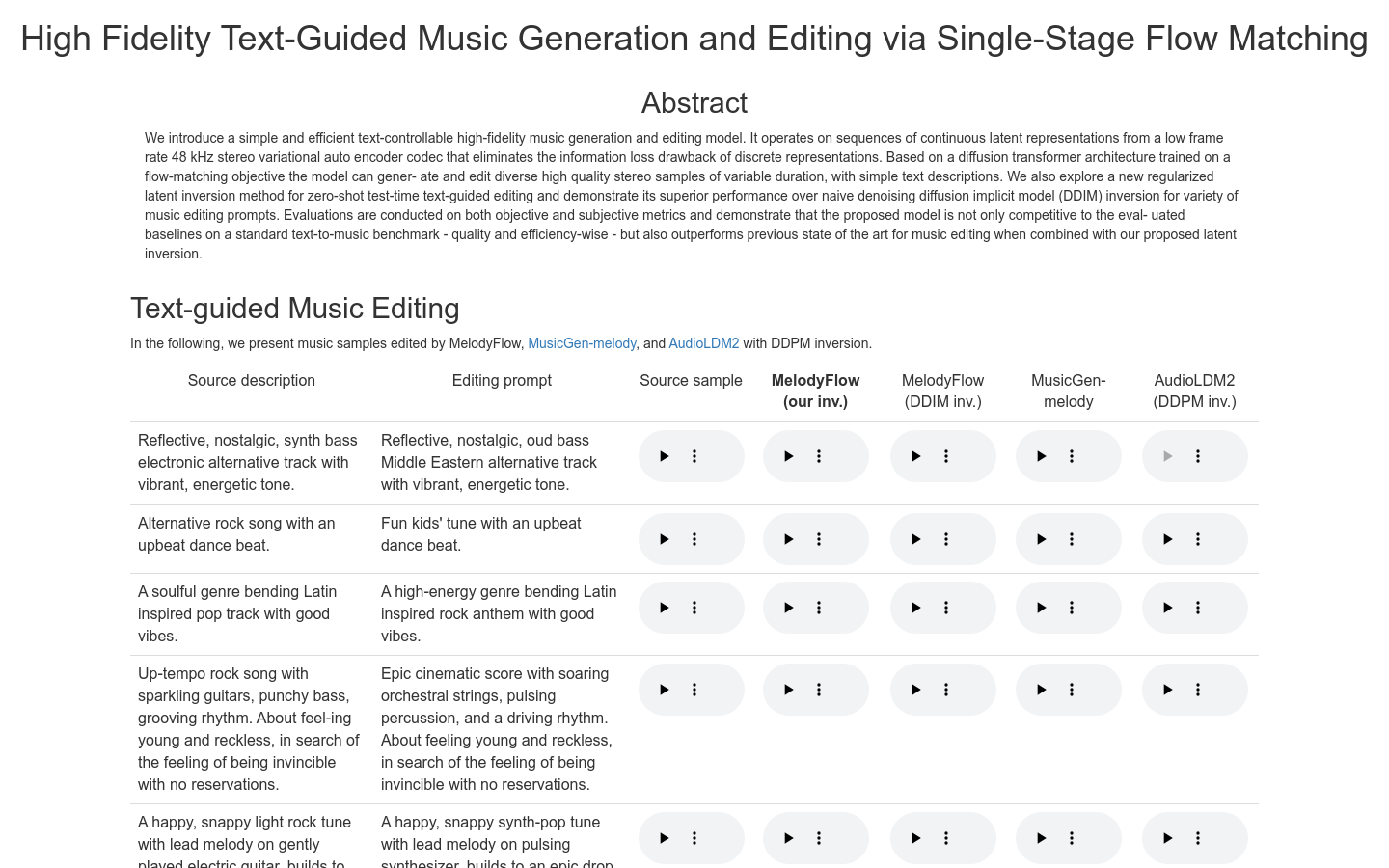 MelodyFlowMelodyFlow是一个基于文本控制的高保真音乐生成和编辑模型,它使用连续潜在表示序列,避免了离散表示的信息丢失问题。该模型基于扩散变换器架构,经过...
MelodyFlowMelodyFlow是一个基于文本控制的高保真音乐生成和编辑模型,它使用连续潜在表示序列,避免了离散表示的信息丢失问题。该模型基于扩散变换器架构,经过... -
 DiffRhythmDiffRhythm 是一种创新的音乐生成模型,利用潜在扩散技术实现了快速且高质量的全曲生成。该技术突破了传统音乐生成方法的限制,无需复杂的多阶段架构...
DiffRhythmDiffRhythm 是一种创新的音乐生成模型,利用潜在扩散技术实现了快速且高质量的全曲生成。该技术突破了传统音乐生成方法的限制,无需复杂的多阶段架构... -
 Audio to Photoreal EmbodimentAudio to Photoreal Embodiment是一个生成全身照片级人形化身的框架。它根据对话动态生成面部、身体和手部的多种姿势动作。其方法...
Audio to Photoreal EmbodimentAudio to Photoreal Embodiment是一个生成全身照片级人形化身的框架。它根据对话动态生成面部、身体和手部的多种姿势动作。其方法... -
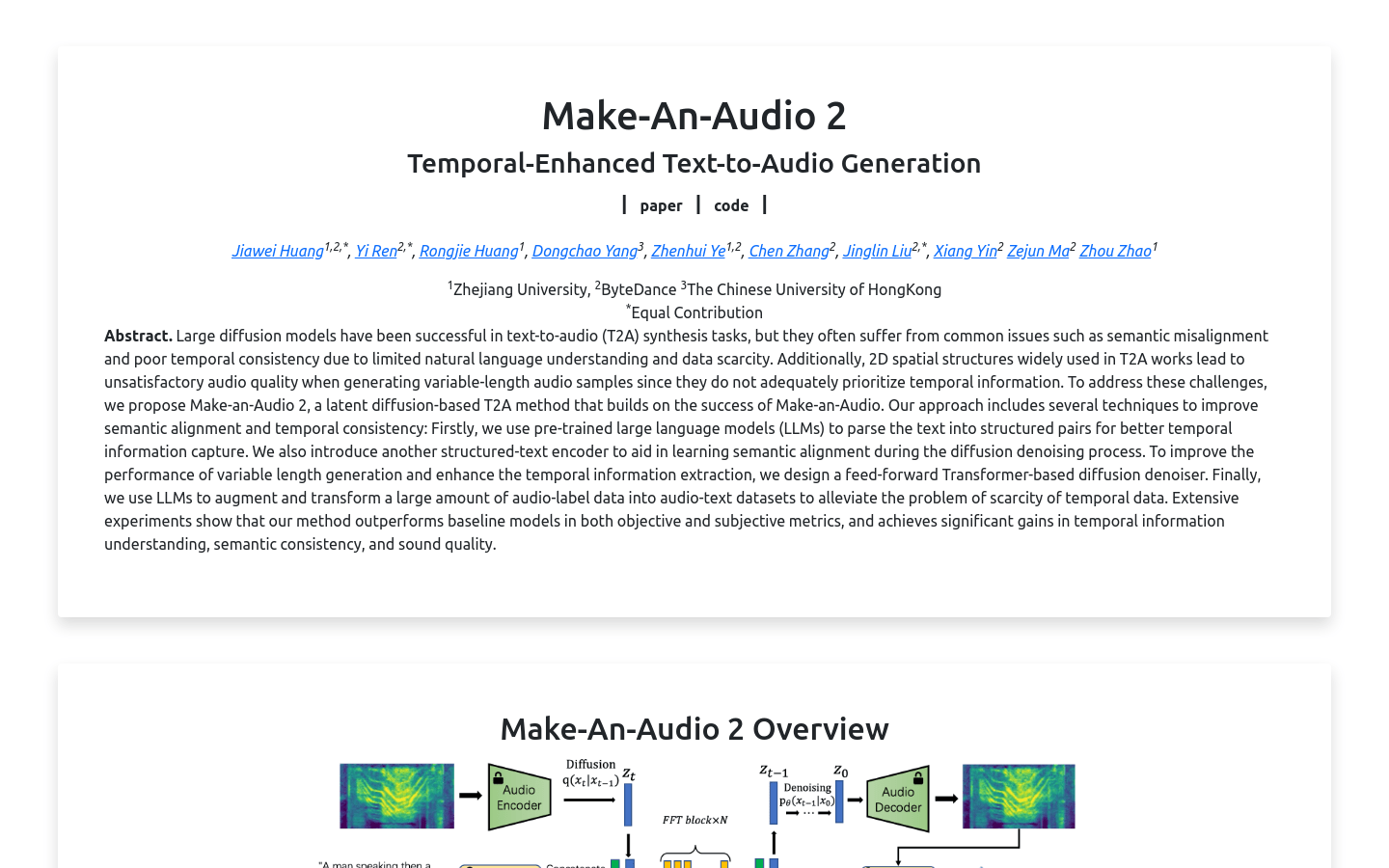 Make-An-Audio 2Make-An-Audio 2是一种基于扩散模型的文本到音频生成技术,由浙江大学、字节跳动和香港中文大学的研究人员共同开发。该技术通过使用预训练的大型...
Make-An-Audio 2Make-An-Audio 2是一种基于扩散模型的文本到音频生成技术,由浙江大学、字节跳动和香港中文大学的研究人员共同开发。该技术通过使用预训练的大型... -
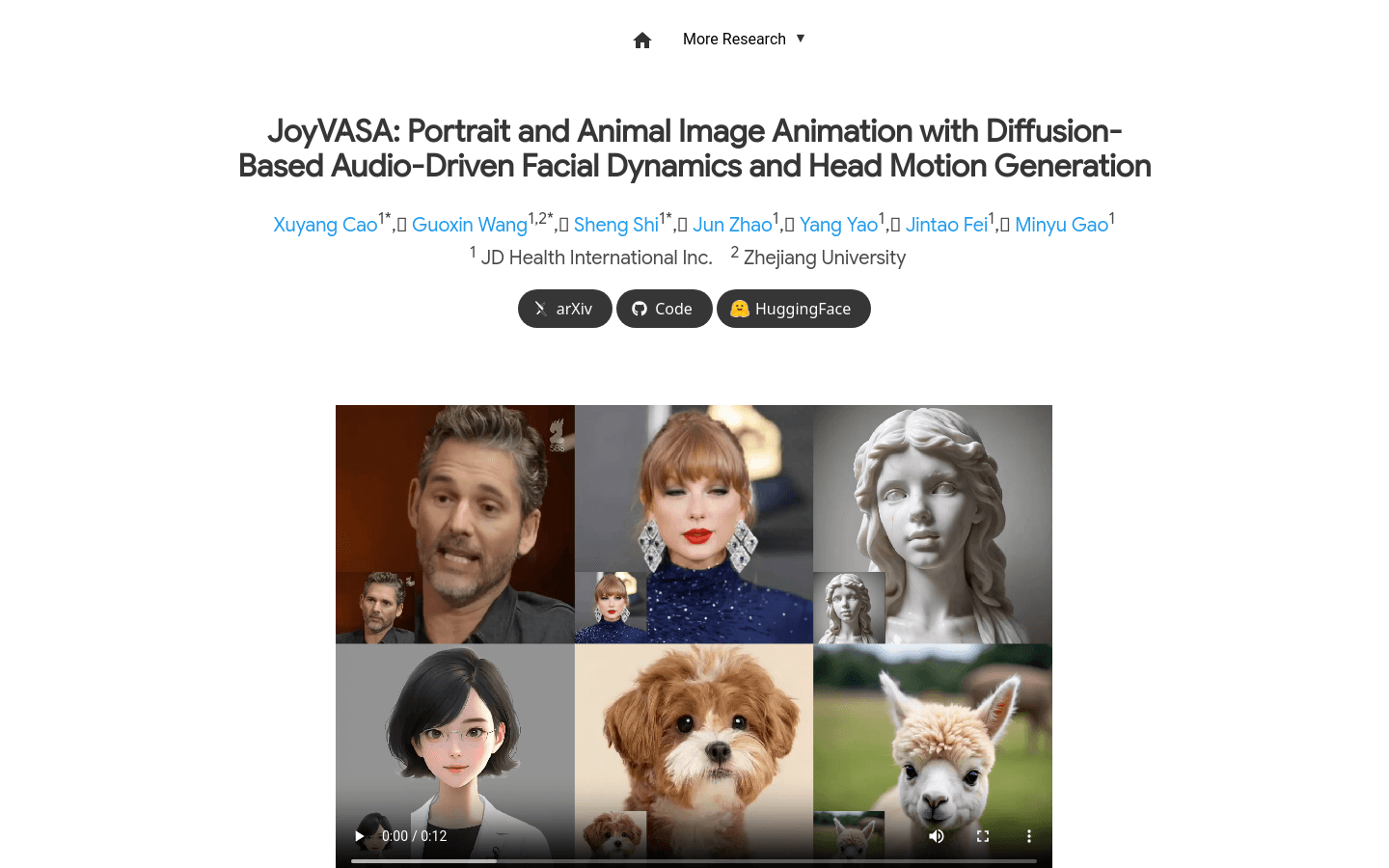 JoyVASAJoyVASA是一种基于扩散模型的音频驱动人像动画技术,它通过分离动态面部表情和静态3D面部表示来生成面部动态和头部运动。这项技术不仅能够提高视频质量...
JoyVASAJoyVASA是一种基于扩散模型的音频驱动人像动画技术,它通过分离动态面部表情和静态3D面部表示来生成面部动态和头部运动。这项技术不仅能够提高视频质量... -
 StyleTTS 2StyleTTS 2 是一款文本转语音(TTS)模型,使用大型语音语言模型(SLMs)进行风格扩散和对抗训练,实现了人级别的 TTS 合成。它通过扩散...
StyleTTS 2StyleTTS 2 是一款文本转语音(TTS)模型,使用大型语音语言模型(SLMs)进行风格扩散和对抗训练,实现了人级别的 TTS 合成。它通过扩散...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
