收集全球10,000⁺个好用的AI软件
-
 ElevenLabs Audio Isolation APIAudio Isolation 是 ElevenLabs 提供的一项在线音频处理服务,专注于从音频中分离出人声或背景音乐。这项技术在音乐制作、视频后期...
ElevenLabs Audio Isolation APIAudio Isolation 是 ElevenLabs 提供的一项在线音频处理服务,专注于从音频中分离出人声或背景音乐。这项技术在音乐制作、视频后期... -
 StreamVCStreamVC是由Google研发的实时低延迟语音转换解决方案,能够在保持源语音内容和韵律的同时,匹配目标语音的音色。该技术特别适合实时通信场景,如...
StreamVCStreamVC是由Google研发的实时低延迟语音转换解决方案,能够在保持源语音内容和韵律的同时,匹配目标语音的音色。该技术特别适合实时通信场景,如... -
 Qwen2-AudioQwen2-Audio是由阿里云提出的大型音频语言模型,能够接受各种音频信号输入,并根据语音指令进行音频分析或直接文本回复。该模型支持两种不同的音频交...
Qwen2-AudioQwen2-Audio是由阿里云提出的大型音频语言模型,能够接受各种音频信号输入,并根据语音指令进行音频分析或直接文本回复。该模型支持两种不同的音频交... -
 SenseVoiceSmallSenseVoiceSmall是一款具备多种语音理解能力的语音基础模型,包括自动语音识别(ASR)、口语语言识别(LID)、语音情感识别(SER)和音...
SenseVoiceSmallSenseVoiceSmall是一款具备多种语音理解能力的语音基础模型,包括自动语音识别(ASR)、口语语言识别(LID)、语音情感识别(SER)和音... -
 Stable Audio Open demoStable Audio Open 是一个能够从文本提示生成长达47秒的立体声音频的技术。它包含三个主要组件:一个将波形压缩到可管理序列长度的自编码器...
Stable Audio Open demoStable Audio Open 是一个能够从文本提示生成长达47秒的立体声音频的技术。它包含三个主要组件:一个将波形压缩到可管理序列长度的自编码器... -
 MaskVATMaskVAT是一种视频到音频(V2A)生成模型,它利用视频的视觉特征来生成与场景匹配的逼真声音。该模型特别强调声音的起始点与视觉动作的同步性,以避免...
MaskVATMaskVAT是一种视频到音频(V2A)生成模型,它利用视频的视觉特征来生成与场景匹配的逼真声音。该模型特别强调声音的起始点与视觉动作的同步性,以避免... -
 Udio v1.5Udio v1.5是一个音乐创作平台的高级版本,它在v1的基础上进行了多项改进,包括提高音质、提供音调控制、改善全球语言支持等。它生成48kHz立体声...
Udio v1.5Udio v1.5是一个音乐创作平台的高级版本,它在v1的基础上进行了多项改进,包括提高音质、提供音调控制、改善全球语言支持等。它生成48kHz立体声... -
 AudioForge AIAudioForge AI是一个专注于音乐制作的智能平台,利用先进的人工智能技术,帮助音乐制作人和爱好者提高音乐创作的效率和质量。它通过自动化处理音频...
AudioForge AIAudioForge AI是一个专注于音乐制作的智能平台,利用先进的人工智能技术,帮助音乐制作人和爱好者提高音乐创作的效率和质量。它通过自动化处理音频... -
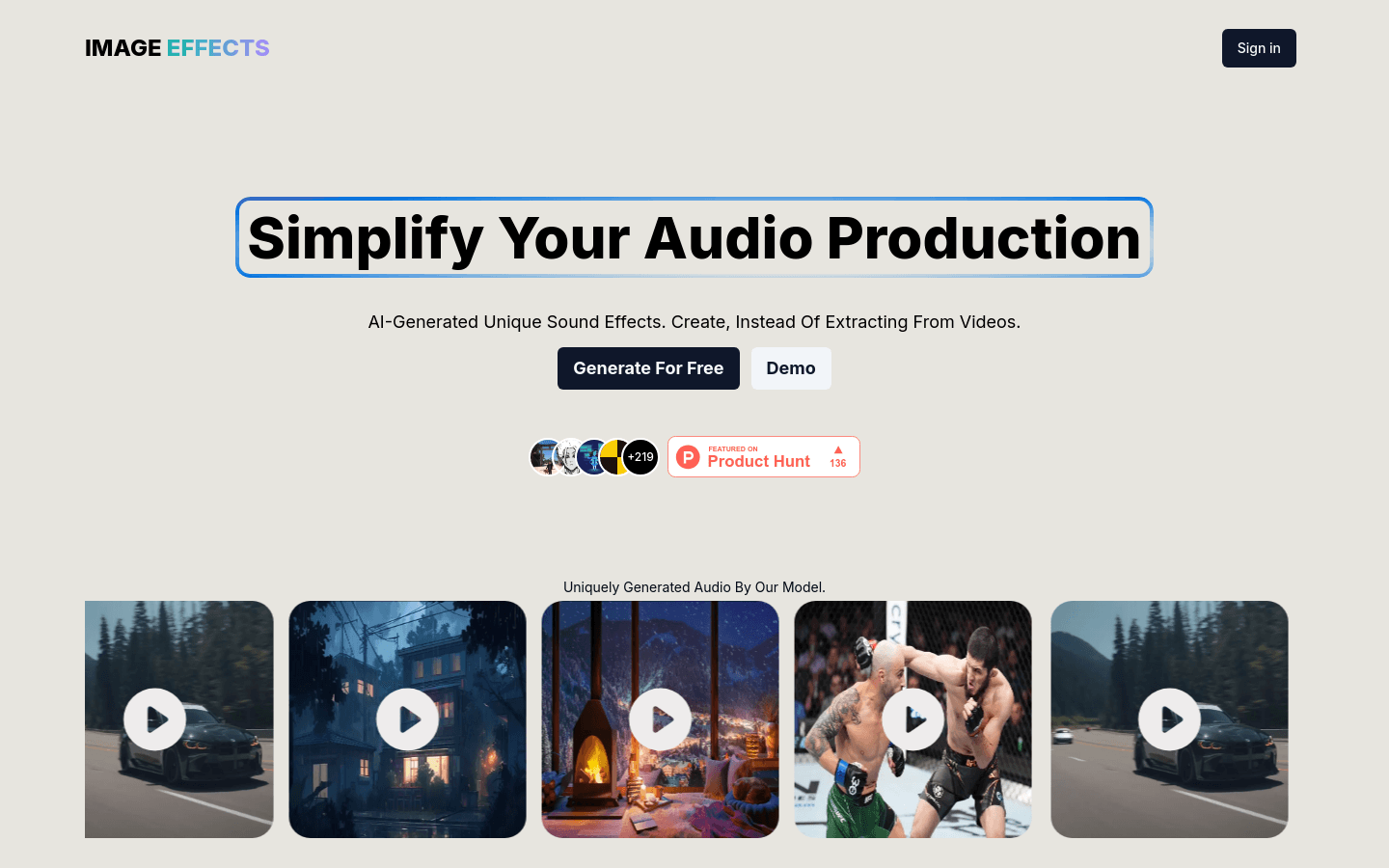 Simplify Your Audio ProductionSimplify Your Audio Production是一个利用人工智能技术生成独特音效的网站,它允许用户通过文本描述或上传图片来创建个性化的音...
Simplify Your Audio ProductionSimplify Your Audio Production是一个利用人工智能技术生成独特音效的网站,它允许用户通过文本描述或上传图片来创建个性化的音... -
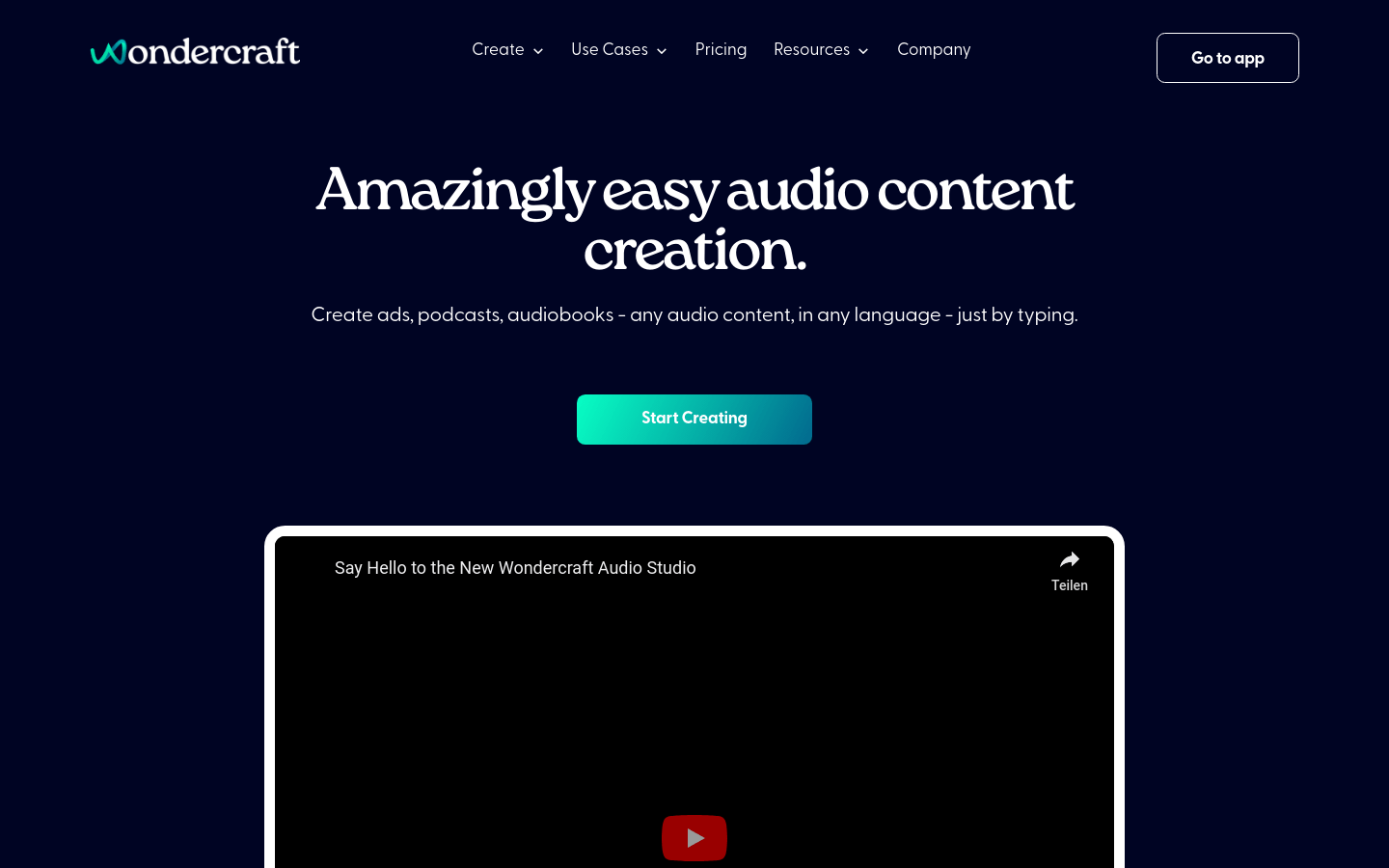 WondercraftWondercraft是一个创新的在线服务,能够将作者的书稿转化为听起来像作者本人声音的语音阅读。这项技术不仅节省了作者在录音棚录制和雇佣音频专家编辑...
WondercraftWondercraft是一个创新的在线服务,能够将作者的书稿转化为听起来像作者本人声音的语音阅读。这项技术不仅节省了作者在录音棚录制和雇佣音频专家编辑... -
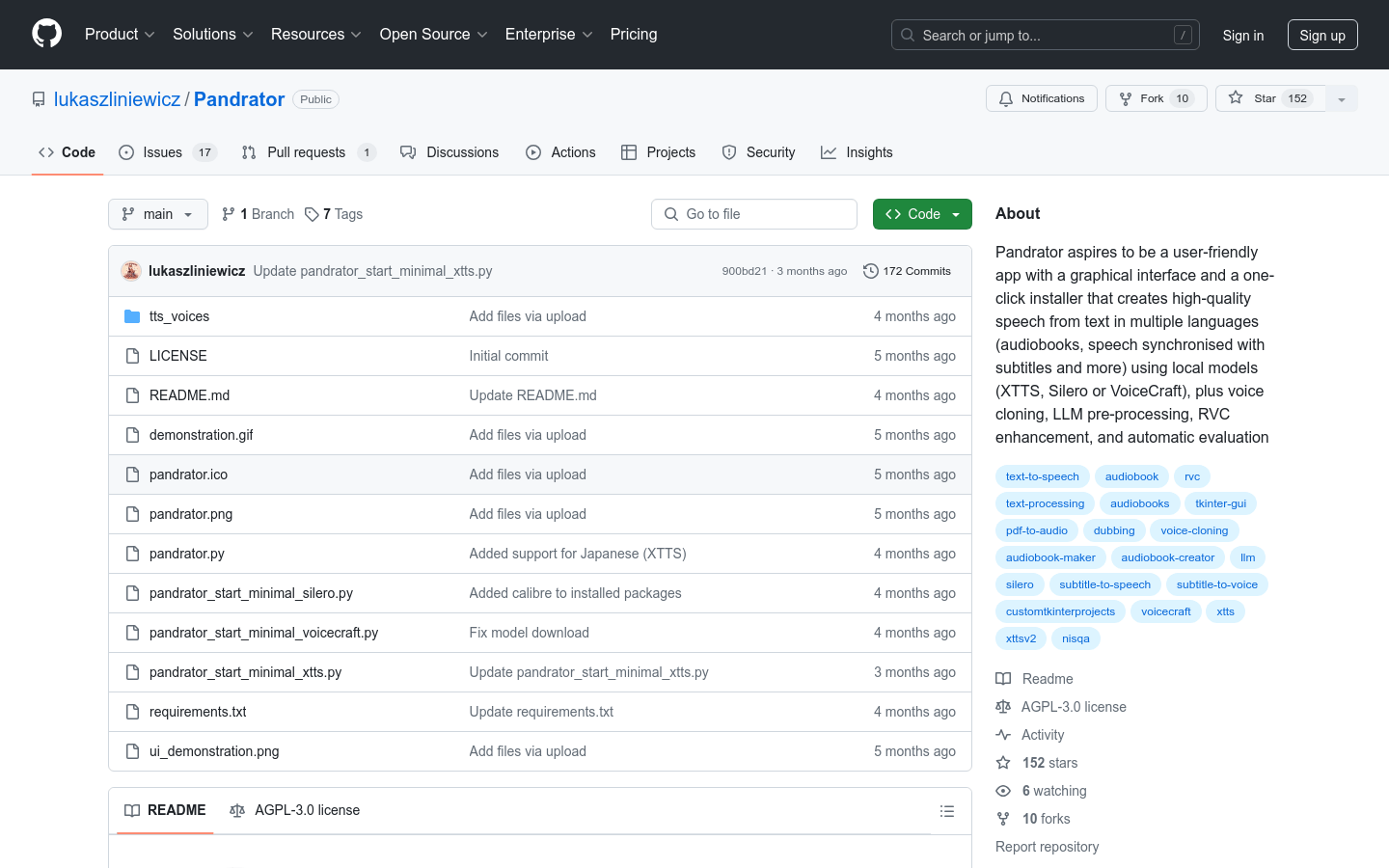 PandratorPandrator 是一个基于开源软件的工具,能够将文本、PDF、EPUB 和 SRT 文件转换成多种语言的语音音频,包括语音克隆、基于LLM的文本预...
PandratorPandrator 是一个基于开源软件的工具,能够将文本、PDF、EPUB 和 SRT 文件转换成多种语言的语音音频,包括语音克隆、基于LLM的文本预... -
 LabelULabelU是一个开源的数据标注工具,适用于需要对图像、视频、音频等数据进行高效标注的场景,以提升机器学习模型的性能和质量。它支持多种标注类型,包括标...
LabelULabelU是一个开源的数据标注工具,适用于需要对图像、视频、音频等数据进行高效标注的场景,以提升机器学习模型的性能和质量。它支持多种标注类型,包括标...
AI爱好者的一站式人工智能AI工具箱,累计收录全球10,000⁺好用的AI工具软件和网站,方便您更便捷的探索前沿的AI技术。本站持续更新好的AI应用,力争做全球排名前三的AI网址导航网站,欢迎您成为我们的一员。
